
The Power of Lampshading
I enjoyed this blog post from Shawn. Lampshading is apparently the idea of a TV show calling attention to some weakness (like an implausible plot point) so that the show can move on. By calling it out, it avoids criticism by demonstrating the self-awareness. For developers, Shawn notes, it’s like admitting to your teammates/boss that you don’t know some particular technology so the team can move on.
Not only is this useful, it’s powerful. Higher-ups need to call out anything they don’t understand because their job is literally asking the right questions and making sure clarity is present for both customers and reports. Juniors need to use it in order to grow.
I feel like this is easier to pull off the further you are on the polarity of junior and senior. If you’re super new, people are like, yeah it makes sense that they don’t know that thing. If you’re highly (and deservedly) senior, people are like, wow this obviously and incredibly knowledgeable human has a gap in their skillset — how relatable and humble of them to say it. I would hope lampshading is useful for everyone, but I could see how people square in the middle might have trouble pulling it off.
Direct Link to Article — Permalink
The post The Power of Lampshading appeared first on CSS-Tricks.
You can support CSS-Tricks by being an MVP Supporter.

It’s Always Year Zero
In the short term, opinions about technology often follow a compressed form of Laver’s Law:
- Everything just before me was completely broken.
- Everything that comes after me is completely unnecessary.
- Everything I use right now is perfectly fine; stop changing things.
We tend to judge things based on where we started, our personal “Year Zeros.” But what’s “Year Zero” for us isn’t “Year Zero” for others. And in the fullness of time, the good ideas win out and hindsight judges them retrospectively obvious.
In 2020, I learned that it’s always Year Zero when it comes to building websites.
In “The Third Age of JavaScript” I speculated about a new wave of web developer tools enabled by the confluence of multiple trends:
- The end of “JavaScript tools in JavaScript” (and the rise of TypeScript/Rust/Go)
- Collapsing layers of tooling
- Neo-isomorphic JavaScript (make it easy to move JavaScript between client/server/build contexts)
- ES Modules everywhere
- The long, slow end of life of Internet Explorer 11
In this framing, 2020 was Year Zero of the Third Age. But what happens in 2021? 2022? What makes me so sure that 2020 was some clear dividing line?
Nothing. There’s always room for innovation. New libraries, new frameworks, new build tools, even new languages. Yes, most of these will go nowhere, and yes, we swing back and forth a lot. But it’s the people who believe that web development isn’t done yet that make the future happen. Not those who play armchair quarterback, nor those who see everything in an odious light. I’d rather side with the people who believe it can be Year Zero than the people who believe Year Zero has passed.

“Year Zero” to me also means keeping a beginner’s mindset and constantly re-examining what I think I know. When I first learned web development, I was told that React was the best framework to build sites, Presentational and Container Components was the right way to do React, and that BEM was the right way to structure CSS. As a newcomer at Year Zero, I assumed that any discomfort I felt with the orthodoxy was my fault. Flash forward to this year and and my most popular articles are about Svelte and Tailwind questioning that conventional wisdom. No one gave me permission to do that. It took years to learn that I could dare to disagree with my mentors and give that permission to myself.
I feel this most of all for the newcomers to our industry. Every year there are about ~350k freeCodeCamp, ~100k university and ~35k bootcamp grads. It’s Year Zero for them. Or how about our end users — the millions of non-developers who every year have more of their world consumed by the buggy, slow software we make? It’s Year Zero for them.
It’s also Year Zero for web development in the broader arc of human history. The web is only 30 years old. We’ve had over 300 years refining modern physics, and yet there are still things we know we don’t know. It is such early days for the web.
Let’s stop pretending what we know is absolute truth and that what we have is the end state of things. It’s Always Year Zero.
The post It’s Always Year Zero appeared first on CSS-Tricks.
You can support CSS-Tricks by being an MVP Supporter.

How Redux Reducers Work
In this tutorial, we’re going to learn the concept of reducers and how they work, specifically in React applications. In order to understand and better use Redux, a solid understanding of reducers is essential. Reducers provide a way to update an application’s state using an action. It is an integral part of the Redux library.
This tutorial is for developers who want to learn more about Redux Reducers. An understanding of React and Redux would be beneficial. At the end of the tutorial, you should have a better understanding of the role Reducers play in Redux. We’ll be writing code demos and an application to better understand Reducers and how it affects the state in an application.
What Is A Reducer
A Reducer is a pure function that takes the state of an application and action as arguments and returns a new state. For example, an authentication reducer can take an initial state of an application in form of an empty object and an action that tells it that a user has logged in and returned a new application state with a logged-in user.
Pure functions are functions that do not have any side effects and will return the same results if the same arguments are passed in.
Below is an example of a pure function:
const add = (x, y) => x + y;
add(2, 5);The example above returns a value based on the inputs, if you pass 2 and 5 then you’d always get 10, as long as it’s the same input nothing else affects the output you get, that’s an example of a pure function.
Below is an example of a reducer function that takes in a state and an action.
const initialState = {};
const cartReducer = (state = initialState, action) => {
// Do something here
}Let’s define the two parameters that a reducer takes in, state and action.
State
A state is the data that your component(s) is working with — it holds the data that a component requires and it dictates what a component renders. Once a state object changes, the component re-renders. If an application state is managed by Redux, then the reducer is where state changes happen.
Action
An action, is an object that contains the payload of information. They are the only source of information for the Redux store to be updated. Reducers update store based on the value of the action.type. Here we will define the action.type as ADD_TO_CART.
According to the official Redux documentation, actions are the only things that trigger changes in a Redux application, they contain the payload for changes to an application store. Actions are JavaScript objects that tell Redux the type of action to be performed, usually they’re defined as functions like the one below:
const action = {
type: 'ADD_TO_CART',
payload: {
product: 'margarine',
quantity: 4
}
}The code above is a typical payload value that contains what a user is sending and it will be used to update the state of the application. As you can see from above, the action object contains the type of action and a payload object that would be necessary for this particular action to be performed.
Updating State Using Reducers
To show how reducers work, let’s look at the number counter below:
const increaseAction = {
type: 'INCREASE',
};
const decreaseAction = {
type: 'DECREASE'
};
const countReducer = (state = 0, action) => {
switch(action.type){
case INCREASE:
return state + 1;
case DECREASE :
return state -1;
default:
return state;
}
};In the code above, increaseAction and decreaseAction are actions used in the reducer to determine what the state is updated to. Next, we have a reducer function called countReducer, which takes in an action and an initial state whose value is 0. If the value of action.type is INCREASE, we return a new state that is incremented by 1, else if it is DECREASE a new state that is decremented by 1 is returned. In cases where none of those conditions are meant, we return state.
Updating State Using Reducers: The Spread Operator
State can’t be directly changed, to create or update state, we can use the JavaScript spread operator to make sure we don’t change the value of the state directly but instead to return a new object that contains a state passed to it and the payload of the user.
const contactAction = {
type: 'GET_CONTACT',
payload: ['0801234567', '0901234567']
};
const initialState = {
contacts: [],
contact: {},
};
export default function (state = initialState, action) {
switch (action.type) {
case GET_CONTACTS:
return {
...state,
contacts: action.payload,
};
default:
return state;
}In the code above, we are using a spread operator to make sure we don’t change the state value directly, this way we can return a new object that is filled with the state that is passed to it and the payload that’s sent by the user. By using a spread operator, we can make sure that the state stays the same as we add all new items to it and also replace the contacts field in the state if it was present before.
Redux Reducers In Action — A Demo
To better understand Redux Reducers and how they work, we will be implementing a simple Movie details finder app, the code and working version can be found here on Codesandbox. To get started, go to your terminal and initialize a react app using the command below:
create-react-app movie-detail-finderOnce our project initialized, next let’s install the packages we’d need for our application.
npm i axios reactstrap react-redux redux redux-thunkOnce, the packages are installed, let’s start our development server using the command:
npm startThe above command should start our project development server in our browser. Next let’s open our project in our text editor of choice, inside our project src folder, delete the following files: App.css, App.test.js, serviceWorker.js and setupTests.js. Next, let’s delete all code that references the deleted files on our App.js.
For this project, we will be using Open Movie Database API to get our movie information, content and images for our application, here is a link to the API, you’d need to register and get access keys in order to use it for this application, Once you’re done, let’s proceed with our application by building components.
Building App Components
First, inside of our src folder in our project directory, create a folder called components and inside the folder, let’s create two folders called Movie and Searchbar, our component should look like the image below:

Building Movie Component
Let’s build the Movies component, which will outline the structure of the movie details we will be getting from our API. To do this, inside the Movies folder of our component, create a new file Movie.js, next create a class based component for the API results, let’s do that below.
import React, { Component } from 'react';
import { Card, CardImg, CardText, CardBody, ListGroup, ListGroupItem, Badge } from 'reactstrap';
import styles from './Movie.module.css';
class Movie extends Component{
render(){
if(this.props.movie){
return (
<div className={styles.Movie}>
<h3 className="text-center my-4">
Movie Name: {this.props.movie.Title}
</h3>
<Card className="text-primary bg-dark">
<CardImg className={styles.Img}
top src={this.props.movie.Poster}
alt={this.props.movie.Title}/>
<CardBody>
<ListGroup className="bg-dark">
<ListGroupItem>
<Badge color="primary">Actors:</Badge>
{this.props.movie.Actors}
</ListGroupItem>
<ListGroupItem>
<Badge color="primary">Genre:</Badge>
{this.props.movie.Genre}
</ListGroupItem>
<ListGroupItem>
<Badge color="primary">Year:</Badge>
{this.props.movie.Year}
</ListGroupItem>
<ListGroupItem>
<Badge color="primary">Writer(s):</Badge>
{this.props.movie.Writer}
</ListGroupItem>
<ListGroupItem>
<Badge color="primary">IMDB Rating:</Badge>
{this.props.movie.imdbRating}/10
</ListGroupItem>
</ListGroup>
<CardText className="mt-3 text-white">
<Badge color="secondary">Plot:</Badge>
{this.props.movie.Plot}
</CardText>
</CardBody>
</Card>
</div>
)
}
return null
}
}
export default Movie;In the code above, Using components from the package reactstrap, you can check out the documentation here. We built a Card component that includes the movie name, Image, genre, actor, year, movie writer, rating, and plot. To make it easier to pass data from this component, we built data to be as props to other components. Next, let’s build our Searchbar component.
Building Our Searchbar Component
Our Searchbar component will feature a search bar and a button component for searching movie components, let’s do this below:
import React from 'react';
import styles from './Searchbar.module.css';
import { connect } from 'react-redux';
import { fetchMovie } from '../../actions';
import Movie from '../Movie/Movie';
class Searchbar extends React.Component{
render(){
return(
<div className={styles.Form}>
<div>
<form onSubmit={this.formHandler}>
<input
type="text"
placeholder="Movie Title"
onChange={e => this.setState({title: e.target.value})}
value={this.state.title}/>
<button type="submit">Search</button>
</form>
</div>
<Movie movie={this.props.movie}/>
</div>
)
}
}In the code above, we are importing connect from react-redux which is used to connect a React component to the Redux store, provides the component with information from the store and also provides functions used to dispatch actions to the store. Next, we imported the Movie component and a function fetchMovie from actions.
Next, we have a form tag with an input box for entering our movie titles, using the setState hook from React, we added an onChange event and value that will set the state of title to the value entered in the input box. We have a button tag to search for movie titles and using the Movie component that we imported, we passed the properties of the component as props to the result of the search.
Next for us is to write a function to submit our movie title to the API in order to send results to us, we also need to set the initial state of the application. let’s do that below.
class Searchbar extends React.Component{
state = {
title: ''
}
formHandler = (event) => {
event.preventDefault();
this.props.fetchMovie(this.state.title);
this.setState({title: ''});
}
Here, we set the initial state of the application to empty strings, we created a function formHandler that takes in an event parameter and passes the fetchMovie function from action and setting the title as the new state of the application. To complete our application, let’s export this component using the connect property from react-redux, to do this we’d use the react redux mapToStateProps property to select the part of the data our component would need, you can learn more about mapToStateProps here.
const mapStateToProps = (state) => {
return { movie: state.movie }
}
export default connect(mapStateToProps, { fetchMovie })(Searchbar)Let’s add styles to our form by creating a file Searchbar.module.css and adding the styles below:
.Form{
margin: 3rem auto;
width: 80%;
height: 100%;
}
input{
display: block;
height: 45px;
border: none;
width: 100%;
border-radius: 0.5rem;
outline: none;
padding: 0 1rem;
}
input:focus, select:focus{
border: 2px rgb(16, 204, 179) solid;
}
.Form button{
display: block;
background: rgb(16, 204, 179);
padding: 0.7rem;
border-radius: 0.5rem;
width: 20%;
margin-top: 0.7rem;
color: #FFF;
border: none;
text-decoration: none;
transition: all 0.5s;
}
button:hover{
opacity: 0.6;
}
@media(max-width: 700px){
input{
height: 40px;
padding: 0 1rem;
}
.Form button{
width: 40%;
padding: 0.6rem;
}
}Once we’ve done the above, our search bar component should look similar to the image below:
Creating Actions For Application
In this component, we will be setting up Redux actions for our application, First, inside the src directory, create a folder named actions and inside the folder, we’d create an index.js file. Here we’d create a function fetchMovie that takes in a title parameter, and fetches movie from the API using Axios. Let’s do this below:
import axios from 'axios';
export const fetchMovie = (title) =>
async (dispatch) => {
const response = await
axios.get(
https://cors-anywhere.herokuapp.com/http://www.omdbapi.com/?t=${title}&apikey=APIKEY);
dispatch({
type: 'FETCH_MOVIE',
payload: response.data
})
}In the code above, we imported axios and created a function called fetchMovie which takes in a title parameter by using async/await so that we can make a request to the API server. We have a dispatch function that dispatches to the Redux the action object that is passed to it. From what we have above, we’re dispatching an action with the type FETCH_MOVIE and the payload that contains the response we got from the API.
NOTE: The apikey in the request will be replaced with your own apikey after registering at OmdbAPI.
Creating App Reducers
In this section, we are going to create reducers for our application.
const fetchMovieReducer = (state = null, action) => {
switch(action.type){
case 'FETCH_MOVIE':
return action.payload;
default:
return state;
}
}
const rootReducer = (state, action) => {
return {
movie: fetchMovieReducer(state, action)
}
}
export default rootReducer;In the code above, we created a fetchMovieReducer that takes in a default state of null and an action parameter, using a switch operator, for case FETCH_MOVIE we will return the value of the action.payload which is the movie we got from the API. If the action we tried performing isn’t in the reducer, then we return our default state.
Next, we created a rootReducer function that will accept the current state and an action as input and returns the fetchMovieReducer.
Putting It Together
In this section, we’d finish our app by creating our redux store in the index.js, let’s do that below:
import React from 'react';
import ReactDOM from 'react-dom';
import { Provider } from 'react-redux';
import { createStore, applyMiddleware } from 'redux';
import thunk from 'redux-thunk';
import App from './App';
import 'bootstrap/dist/css/bootstrap.min.css';
import './index.css';
import reducers from './reducers';
const store = createStore(reducers, applyMiddleware(thunk))
ReactDOM.render(
<Provider store={store}>
<>
<App/>
</>
</Provider>,
document.getElementById('root')
)In the code above, we created the application store using the createStore method by passing the reducer we created and a middleware. Middlewares are addons that allow us to enhance the functionalities of Redux. Here we are making use of the Redux Thunk middleware using applyMiddleware. The Redux Thunk middleware is necessary for our store to do asynchronous updates. This is needed because by default, Redux updates the store synchronously.
To make sure our application knows the exact store to use, we wrapped our application in a Provider component and passed the store as a prop, by doing this, other components in our application can connect and share information with the store.
Let’s add a bit of style to our index.css file.
*{
margin: 0;
padding: 0;
box-sizing: border-box;
}
body{
background: rgb(15, 10, 34);
color: #FFF;
height: 100vh;
max-width: 100%;
}Rendering And Testing A Movie Detail Finder
In this section, we are going to conclude our application by rendering our application in our App.js, to do this, let’s create a class-based component named App and initialize our Searchbar and input field.
import React from 'react';
import Searchbar from './components/Searchbar/Searchbar';
import styles from './App.module.css';
class App extends React.Component{
render(){
return(
<div className={styles.App}>
<h1 className={styles.Title}>Movies Search App</h1>
<Searchbar/>
</div>
)
}
}
export default App;Here, we created an App class based component with a h1 that says Movie Search App and added our Searchbar component. Our application should look like the image below:

A working demo is available on Codesandbox.
Conclusion
Reducers are an important part of Redux state management, with reducers we can write pure functions to update specific areas of our Redux applications without side effects. We’ve learned the basics of Redux reducers, their uses, and the core concept of reducers, state, and arguments.
You can take this further by seeing the documentation on Redux reducers here. You can take this further and build more on Redux reducers, let me know what you build.
Resources

Learning to Simplify
When I first got this writing prompt, my mind immediately started thinking stuff like, “What tech have I learned this year?” But this post isn’t really about tech, because I think what I’ve learned the most about building websites this past year is simplification.
This year, I’ve learned that keeping it simple is almost always the best approach. Heck, I’ve been banging that drum for a while, but this year has really solidified those sort of thoughts. I’m trying to think of a single instance where a complex, technical issue has arisen this year, where the end-solution didn’t come about due to simplification, and I’m coming up blank. Sure, ideas almost always start off over-complicated, but I’m learning more and more that slowing down and refining ideas is the best approach.
Brendan Dawes created this great piece of art, and coincidentally, a copy of it sits on my wall. I think it illustrates my working process perfectly and acts as a constant reminder to refine and simplify.

I run Piccalilli and released my first course this year. I really wanted to self-publish that material, too. Sure, keeping it really simple would have me publishing the course on an existing platform, but I had some red lines. The first being that I had to own everything because if a provider or platform turned out to be ass-hats, then I’d be in a pickle.
Another red line was that my content had to be written, rather than videos, which again, makes owning my own content important, because some platforms can pull the rug from under your feet. A good example is Medium’s ever-changing content access rules and inconsistent paywall behavior.
Finally, the red line of all red lines was this: the content had to be fully accessible and easily accessed. You might be thinking they’re the same thing, but not quite: the easily accessed part means that if you buy content from me, you sure as heck will get to it with as little friction as possible.
This loops me nicely back to keeping things simple. To make access simple for my valued students, I needed to simplify my approach to them accessing content, while locking people out who hadn’t purchased it. My immediate thoughts — naturally — went into some complex architecture that was extremely smart™, because that’s what we do as developers, right? The difference this year versus previous years is that I forced myself to simplify and refine because I wanted to spend as little time and energy as possible writing code — especially code I know is going to haunt me in the future.
So, again, thinking about these red lines, the big caveat is that currently, my site runs off a static site generator — Eleventy, naturally — and my need for simplification along with this caveat led me to an obvious conclusion: use the platform.
In short, I used Service Workers to give people access to content. My site builds twice on Netlify. Once is what you see, over on piccalil.li. But there’s a secret site that is all exposed (it’s not really, it’s like Fort Knox) that has all the content available. When you buy a course, my little API scurries along to that site and finds all the content for it. It then pushes that down to you. Then, the platform takes over because I use the baked-in Cache and Response APIs. I create a Response for each lesson in the course, then stick it in the Cache. This means that whenever you go to a lesson, you get that version that was previously hidden from you. The added bonus to this is that the content is offline-first, too. Handy.
Sure, this solution relies on JavaScript, but heck, not much at all — especially when you compare it to even the simplest projects that produce extremely JavaScript-heavy outputs, like Gatsby et al.
Using the platform is super low maintenance because, y’know, it’s all baked into the browser, so it doesn’t keep me up at night, worrying that it’ll suddenly break if a rogue developer deletes a package. I could have also put together some galaxy brain stuff but that has a huge risk of creating technical debt and breaking at least one of my red lines: make content fully accessible and easily accessed. The platform again, wins.
If I push a big ol’ bundle of JavaScript down the pipe to a low-powered device and/or a slow connection, the chances are that content will not make it, or if it does, it will likely fail to parse. That alienates a lot of people which breaks red lines for me. Sure, building the site with this technology would keep it simple for me, as I wrote it, but utilizing the platform keeps it simple for everyone — especially me, when I need to maintain it. I’m digging that, a lot.
The post Learning to Simplify appeared first on CSS-Tricks.
You can support CSS-Tricks by being an MVP Supporter.

Smashing Podcast Episode 31 With Eve Porcello: What Is GraphQL?
In this episode, we’re talking about GraphQL. What is it, and how does solve some common API problems? I spoke with expert Eve Porcello to find out.
Show Notes
- Eve on Twitter
- Eve’s company Moon Highway
- Learning GraphQL from O’Reilly
- Discover Your Path Through The GraphQL Wilderness – Eve’s GraphQL workshop launching early 2021
Weekly Update
- How To Use MDX Stored In Sanity In A Next.js Website
written by Jason Lengstorf - Building A Conversational N.L.P Enabled Chatbot Using Google’s Dialogflow
written by Nwani Victory - Ethical Considerations In UX Research: The Need For Training And Review
written by Victor Yocco - Making Websites Easier To Talk To
written by Frederick O’Brien - How To Design A Simple UI When You Have A Complex Solution
written by Suzanne Scacca
Transcript
 Drew McLellan: She’s a software engineer, instructor, author, and co-founder of training and curriculum development company, Moon Highway. Her career started writing technical specifications and creating UX designs for web projects. Since starting Moon Highway in 2012, she’s created video content for egghead.io and LinkedIn Learning, and has co-authored the books Learning React and Learning GraphQL for O’Reilly’s Media.
Drew McLellan: She’s a software engineer, instructor, author, and co-founder of training and curriculum development company, Moon Highway. Her career started writing technical specifications and creating UX designs for web projects. Since starting Moon Highway in 2012, she’s created video content for egghead.io and LinkedIn Learning, and has co-authored the books Learning React and Learning GraphQL for O’Reilly’s Media.
Drew: She’s also a frequent conference speaker, and has presented at conferences including React Rally, GraphQL Summit, and OSCON. So we know she’s an expert in GraphQL, but did you know she once taught a polar bear to play chess? My smashing friends, please welcome Eve Porcello.
Drew: Hi Eve, how are you?
Eve Porcello: I’m smashing.
Drew: As I mentioned there, you’re very much an educator in things like JavaScript and React, but I wanted to talk to you today about one of your other specialist areas, GraphQL. Many of us will have heard of GraphQL in some capacity, but might not be completely sure what it is, or what it does, and in particular, what sort of problem it solves in the web stack.
Drew: So set the stage for us, if you will, if I’m a front end developer, where does GraphQL slot into the ecosystem and what function does it perform for me?
Eve: Yeah. GraphQL kind of fits between the front end and the backend. It’s kind of living in the middle between the two and gives a lot of benefits to front end developers and back end developers.
Eve: If you’re a front end developer, you can define all of your front ends data requirements. So if you have a big list of React components, for example, you could write a query. And that’s going to define all of the fields that you would need to populate the data for that page.
Eve: Now with the backend piece, it’s really own, because we can collect a lot of data from a lot of different sources. So we have data in REST APIs, and databases, and all these different places. And GraphQL provides us this nice little orchestration layer to really make sense of the chaos of where all of our data is. So it’s a really useful for kind of everybody all over the stack.
Drew: So it’s basically an API based technology, isn’t it? It sits between your front end and your back end and provide some sort of API, is that correct?
Eve: Yeah, that’s exactly right. Exactly.
Drew: I think, over the last decade, the gold standard for APIs has been rest. So if you have a client side app and you need to populate it with data from the backend, you would build a REST API endpoint and you’d query that. So where does that model fall down? And when might we need GraphQL to come in and solve that for us?
Eve: Well, the problem that GraphQL really helps us with, kind of the golden problem, the golden solution, I guess, that GraphQL provides is that with REST we’re over fetching a lot of data. So if I have slash users or slash products, that’s going to give me back all of the data every time I hit route.
Eve: With GraphQL, we can be a little bit pickier about what data we want. So if I only need four fields from an object that has a hundred, I’m going to be able to really pinpoint those fields and not have to load data into, or load all of that data I should say, into your device, because that’s a lot of extra legwork, for your phone especially.
Drew: I’ve seen and worked with REST APIs in the past that have an optional field where you can pass in a list of the data that you want back, or you can augment what comes back with extra things. And so I guess that’s identifying this problem, isn’t it? That’s saying, you don’t always want the same data back every time. So is it that GraphQL formalizes that approach of allowing the front end to specify what the backend is going to return, in terms of data?
Eve: Yeah, exactly. So your query then becomes how you ask, how you filter, how you grasp for any sort of information from anywhere.
Eve: I also think it’s important to note that we don’t have to tear down all of our REST APIs in order to work with GraphQL really successfully. A lot of the most successful implementations of GraphQL I’ve seen out there, it’s wrappers around REST APIs. And the GraphQL query really gives you a way to think about what data you need. And then maybe some of your data comes from our users and products, examples, some of the data comes from rest, some of it comes from a database.
Drew: I guess the familiar scenario is, you might have an endpoint on your website that returns information about a user to display the header. It might give you their username and their avatar. And you cull that on every page and populate the data, but then you find somewhere else in your app you need to display their full name.
Drew: So you add that to the endpoint and it starts returning that. And then you do your account management section, and you need like their mailing address. So that gets returned by that endpoint as well.
Drew: And before you know it, that endpoint is returning a whole heavy payload that costs quite a lot on the backend to put together, and obviously a lot to download.
Drew: And that’s been culled on every single page just to show an avatar. So I guess that’s the sort of problem that grows over time, that was so easy to fall into, particularly in big teams, that GraphQL, it’s on top of that problem. It knows how to solve that, and it’s designed around solving that.
Eve: Exactly. And yeah, I think that whole idea of a GraphQL Schema, I think is a really, it’s kind of less talked about than the query language part of GraphQL. But I really feel like the Schema in particular gives us this nice type system for API.
Eve: So anybody on the team, managers, front end developers, back end developers, anybody who is really dealing with data can come together, coalesce around what data we actually want to serve up on this API, and then everyone knows what that source of truth is, they can go build their own parts of the app based on that.
Eve: So there’s some tricky Schema management things that come up with that too. But as far as moving from microservices back to monoliths, we’re sort of doing that, but getting all of the benefits we like out of microservices still.
Drew: And do I understand correctly that the typical way of setting up a GraphQL system is that you’d have basically one route, which is the endpoint that you send all your queries to so you’re not having to… Often one of the most difficult things is working out what to name, and what the path should be that this particular query should be at. It’s returning users and products, should it be it slash users something, or slash product something?
Drew: With GraphQL you just have one endpoint that you just fire your queries to and you get back an appropriate response.
Eve: Exactly. Yeah. It’s a single endpoint. I guess, you still are dealing with problems of naming because you’re naming everything in the Schema. But as far as, I feel like a lot of companies who have made big bets on microservices, everyone’s like, what endpoints do we have? Where are they? How are they documented? And with GraphQL, we have one place, one kind of dictionary to look up anything that we want to find out about how the API works.
Drew: So, I’m very familiar with other query languages, like SQL is an obvious example of a query language that a lot of web developers will know. And the queries in that take the form of almost like a command. It’s a text string, isn’t it, Select this from that, where, whatever. What format do the queries take with GraphQL?
Eve: It’s still a tech string, but it doesn’t define where that logic comes from. And a lot of the logic is moved back to the server. So the GraphQL server, the GraphQL API is really responsible for saying, “Go get this data from where it is, filter it based on these parameters.”
Eve: But in the query language, it’s very field oriented. So we just add fields for anything that we want to retrieve. We can put filters on those queries, of course, too. But I think it’s a little less direct about where that information comes from. A lot of the functionality is built into the server.
Drew: So you can mix and match in a query. You can make a request that brings back lots of different types of data in one request. Is that right?
Eve: Yeah, that’s absolutely right. So you could send a query for as many fields as your server would allow, and bring back all sorts of nested data. But that’s really how it works, we connect different types on fields. So I guess we’ll recycle my users and products idea, but the user might have a products field that returns a list of products. All of those are associated with other types as well. So as deeply nested as we want the query to go, we can.
Drew: So does that mean to retrieve the data for a typical view in your web application that might have all sorts of things going on, that you can just make one request to the backend and get that all in one go without needing to make different queries to different endpoints, because it’s all just one thing?
Eve: Yeah. That’s exactly the whole goal, is just a single query, define every field that you want, and then return it in one response.
Drew: And the queries are Jason based? Is that right?
Eve: … Turn it in one response.
Drew: And the queries are JSON based, is that right?
Eve: The query itself is a text string, but it typically returns JSON data. So if I have the fields, then my JSON response matches exactly, and so it’s really clear what you’re getting when you send that query, because the data response looks exactly the same.
Drew: A lot of the queries it seems like are for almost like bare objects, like a customer or a product. Is there a way to specify more complex queries where business logic is controlled at the backend? Say I want to get a list of teams for a user, but only where that user is an admin of a team and where the team plan hasn’t expired, and all those sorts of real constraints that we face in everyday web application development. Can that be achieved with GraphQL?
Eve: Absolutely. So that’s the real exciting, powerful thing about GraphQL is, you can move a lot of that logic to the server. If you had a complex query, some really specific type of user that you wanted to get, all you’d need to do in the Schema is say, “Get complicated user”, and then on the server, there would be a function where you could write all of the logic in whatever language you wanted to. JavaScript is kind of the most popular GraphQL implementation language, but you don’t have to use that at all. So Python, Go, C++, whatever you want to use, you can build a GraphQL server with that. But yeah, you can define as complex a query as you’d like to.
Drew: And I guess that enables you to encapsulate a lot of business logic then in new types of objects. Is that fair? You know, you set up a complicated user and then you don’t need to think what a complicated user is, but you can just keep using that complicated user and know that the business logic is implemented on that. Is that right?
Eve: That’s exactly right. So I think this is really nice for front end folks because they can start to prototype based on that. And then the backend team could go implement those functions to make that work. And then there’s kind of this shared understanding for what that type actually is and who they are, and, “What are the fields on that type?” And everything can be handled by wherever in the stack GraphQL is working. And that’s why it’s not really a front end or a back end technology. It’s really kind of both, and neither.
Drew: It sounds like it’s sort of formalizing the API and the relationship between front end and backend, so everybody’s getting a predictable interface that is standardized.
Eve: Exactly.
Drew: Which I guess in organizations where the front end and the backend are owned by different teams, which isn’t at all uncommon, I guess this approach also enables changes to be made, say, on the front end, it might require different data, without needing somebody who works on the backend to make the changes that correspond to that. You’ve still got this almost infinitely customizable API without requiring any work to be done to change it if you need new data.
Eve: Yeah, exactly right.
Drew: So is the GraphQL server responsible for formatting the response, or do you need to do that in your server side logic?
Eve: So the GraphQL server defines two things. It defines the Schema itself that lives on the server, and then it defines the resolver functions. Those are functions that go get the data from wherever it is. So if I have a REST API that I’m wrapping with GraphQL, the resolver would fetch from that API, transform the data however it needed to be, and then return it to the client in that function. You can use any sort of database functions you’d like to on that server as well. So if you have data in a bunch of different places, this is a really nice cohesive spot to put all of that data in and to kind of design all the logic around, “Where’s that data coming? How do we want to transform it?”
Drew: The client says, “I want a complex user”, the server receives that in a query and could say, “Right, I’m going to look up the complex user resolver.” Is that right?
Eve: Mm-hmm (affirmative).
Drew: Which is the function, and then you write your logic that your backend team, or whoever writes the logic inside that function, to do whatever is necessary to return a complex user.
Eve: Yeah, exactly.
Drew: So that could be calling other APIs, it could be querying a database, it could be looking stuff up in cache, or pretty much anything.
Eve: Pretty much anything. And then, as long as that return from the function matches the requirements of the Schema, matches what fields, what types, were returning there, then everything will work nice and harmoniously.
Drew: I guess it gives you a consistent response format across your entire API just by default. You don’t have to design what that looks like. You just get a consistent result.
Eve: Yeah, exactly.
Drew: I think that could be quite a win really, because it can be really difficult to maintain consistency across a big range of API end points, especially in larger teams. Different people are working on different things. Unless you have quite strict governance in place, it can get really complex really quickly, can’t it?
Eve: Yeah, absolutely. And I think that Schema is just such a nice little document to describe everything. You get the automatic benefit of being able to see all of the fields in that Schema whenever you’re trying to send queries to it, because you can send introspection queries and there’s all sorts of nice tools for that, like GraphQL and GraphQL Playground, little tools that you can use to interact with the API’s data.
Eve: But also, if you’ve ever played around with Postman, like to ping a REST API, a lot of those, the documentation doesn’t really exist or it’s tough to find, or things like that. GraphQL really gives you that nice cohesive layer to describe everything that might be part of that API.
Drew: Practically, how do things work on the server side? I mean, I guess you need to run a GraphQL service as part of your infrastructure, but what form does that take? Is it an entire server running on its own port? Or is it just like a library you integrate into your existing Express or Apache or whatever with a route that resolves to that service? How do you implement it?
Eve: Yeah, it’s an actual server. So kind of the most popular GraphQL implementations are Node.js servers. When GraphQL as a spec was released, the team released this reference implementation in JavaScript, kind of a Node server that served as the guidelines for all these other ones who have popped up. But yeah, you can run these servers on their own instances. You can put them on Lambda. So there’s Apollo Server Express, there’s Apollo Server Lambda; all sorts of different types of implementations that you can use to actually run this thing.
Drew: So you mentioned briefly before the concept of a Schema that the server has.
Eve: Yeah.
Drew: That gives you the ability to describe your types more strictly than just, you know, mapping a name to a resolver. There’s more involved there, is there?
Eve: Yeah. There’s a full language. So I’ve referenced the spec and I didn’t describe what it is. GraphQL itself is a spec that describes the query language and the Schema definition language. So it has its own syntax. It has its own rules for defining these types.
Eve: When you’re using the Schema definition language, you basically use all of the features of that language to think about, what are the types that are part of the API? It’s also where you define the queries, the mutations, which are the verbs, like the actions, create account login, things like that. And even GraphQL subscriptions, which are another cool thing, real time GraphQL that you can define right there in the Schema.
Eve: So yeah, the Schema really is super important. And I think that it gives us this nice type enforcement across our full Stack application, because as soon as you start to deviate from those fields and from those types, you start to see errors, which is, in that case, good, because you’re following the rules of the Schema.
Drew: Is there any crossover between that and TypeScript? Is there a sort of synergy between the two there?
Eve: Absolutely. So if you’re a person who talks about GraphQL a lot, sometimes people will tell you that it’s bad, and they’ll come up to you publicly, when you could do that, and talk about how GraphQL is no good. But a lot of times they skip out on the cool stuff you get from types. So as far as synergy with TypeScript goes, absolutely, you can auto-generate types for your front end application using the types from the Schema. So that’s a huge win because you can not only generate it the first time, which gives you great interoperability with your front end application, but also, as things change, you can regenerate types and then build to reflect those changes. So yeah, I think those things fit really nicely together as types start to be kind of the defacto rule.
Eve: … to be kind of the defacto rule in JavaScript, they fit nicely together.
Drew: It seems to be a sort of ongoing theme with the way that TypeScript has been designed … that’s not TypeScript, sorry. GraphQL has been designed that there’s a lot of about formalizing the interaction between the front end and the back end. And it’s coming as a solution in between the just creates consistency and a formalization of what so far has been otherwise a fairly scrappy experience with rest for a lot of people. One thing that we always have to keep in mind when writing client-side apps is that the code is subject to inspection and potentially modification. And having an API where the client can just request data could be dangerous. Now, if you can specify what fields you want, maybe that could be dangerous. Where in the sort of the whole stack, would you deal with the authorization of users and making sure that the business rules around your data enforced?
Eve: You would deal with that all on the server. So, that could happen in many different ways. You don’t have to use one off strategy, but your resolvers will handle your authorization. So that could mean wrapping an existing off REST API, like a service like Auth0 or something you’ve built on your own. That could mean interacting with an OAuth, like GitHub or Facebook or Google login, those types of things that involves kind of passing tokens back and forth with resolvers. But oftentimes that will be built directly into the Schema. So the Schema will say, I don’t know, we’ll create a login mutation. And then I send that mutation with my credentials and then on the server, all of those credentials are verified. So the client doesn’t have to worry so much, maybe a little bit of passing tokens and things like that. But most of that is just built into the server.
Drew: So essentially, that doesn’t really change compared to how we’re building rest endpoints at the moment. Rest as a technology, well, it doesn’t really deal with authorization either and we have middleware and things on the server that deals with it. And it’s just the same with GraphQL. You just deal with it. Are there any conventions in GraphQL community for doing that? Are there common approaches or is it all over the place for how people choose to implement it?
Eve: It’s honestly all over the place. I think most times you’ll see folks building off into the Schema and by that I mean, representing those types and authorized users versus regular users building those types into the Schema itself. But you’ll also see a lot of folks using third-party solutions. I mentioned Auth0. A lot of folks will kind of offload their authorization on to companies who are more focused on it, particularly smaller companies, startups, things like that. But you’ll also see bigger companies starting to create solutions for this. So AWS, Amazon has AppSync, which is their flavor of GraphQL, and they have author rolls built directly into AppSync. And that’s kind of cool just to be able to, I don’t know, not have to worry about all of that stuff or at least provide an interface for working with that. So a lot of these ecosystem tools have, I think authorization is such a big topic in GraphQL. They’ve seen kind of the need, the demand for auth solutions and standard approaches to handling auth on the graph.
Drew: I guess there’s hardly a, an implementation out there that doesn’t need some sort of authorization. So yeah, it’s going to be a fairly common requirement. We’re all sort of increasingly building componentized applications, particularly when we’re using things React and View and what have you. And the principle of loose coupling leaves us with lots of components that don’t necessarily know what else is running on the page around them. Is there a danger as a result of that, you could end up with lots of components querying for the same data and making multiple requests? Or is it just an architectural problem in your app that you need to solve for that? Are there sort of well-trodden solutions for dealing with that?
Eve: Well, I think because GraphQL for the most part, not 100% of the solutions, but almost every GraphQL query is sent over HTTP. So if you want to track down where those multiple requests are happening, it’s probably a fairly familiar problem to folks who are using rest data for their applications. So there are some tools like Paulo Client Dev Tools and Urkel Dev Tools for front end developers who are like, “What’s going on? Which queries are on this page?” That gives you really clear insights into what’s happening. There’s kind of several schools of thought with that. Do we create one big, huge query for all of the data for the page? Or do we create smaller queries to load data for different parts of the app? Both as you might imagine, they have their own drawbacks, just because if you have a big query, you’re waiting for more fields.
Eve: If you have smaller queries, there may be collisions between what data you’re requiring. But I think, and not to go off on too much of a tangent, but I’m there already. So the there’s something called the Deferred Directive that’s coming to the GraphQL spec and the Deferred Directive is going to help with kind of secondarily loading content. So let’s say you have some content at the top of the page, the super important content that you want to load first. If you add that to your query and then any subsequent fields get the deferred directive on that. It’s just a little decorator that you would add to a field, that will then say, “All right, load the important data first, then hold up and load the second data second.” And it kind of gives you this, it’s the appearance of kind of streaming data to your front end, so that there’s perceived performance, there’s interactivity. People are seeing data right away versus waiting for every single field to load for the page, which yeah, it could be a problem.
Drew: Yeah. I guess that enables you to architect pages where everything that’s … we don’t like to talk too much about the viewport, but it is everything above the fold, you could prioritize, have that load in and then secondarily load in everything sort of further down. So, we’ve talked a lot about querying data. One of the main jobs of an API is sending new and modified data back to the server for persistence. You mentioned briefly mutations earlier. That’s the terminology that’s GraphQL uses for writing data back to the server?
Eve: Exactly. So any sort of changes we want to make to the data, anything we want to write back to the server, those are mutations, and those are all just like queries, they’re named operations that live on the server. So you can think about what are all the things we want our users to be able to do? Represent those with mutations. And then again on the server, write all the functions that make that stuff work.
Drew: And is that just as simple as querying for data? Calling a mutation is just as easy?
Eve: Yeah. It’s part of the query language. It looks pretty much identical. The only difference is, well, I guess queries take in filters. So mutations taken what looked like filters in the query itself. But those are responsible for actually changing data. An email and a password might get sent with a mutation, and then the server collects that and then uses that to authorize the user.
Drew: So, just as before, you’re creating a resolver on the backend to deal with that and to do whatever needs to be done. One common occurrence when writing data is that you want to commit your changes and then re-query to get the sort of current state of it. Does GraphQL have a good workflow for that?
Eve: It sort of lives in the mutation itself. So, a lot times when creating your Schema you’ll create the mutation operation. I’ll stick with log-in, takes in the email and the password. And the mutation itself returned something. So it could return something as simple as a Boolean, this went well, or this went badly, or it could return an actual type. So oftentimes you’ll see the mutation like the log-in mutation, maybe it returns a user. So you get all the information about the user once they’re logged in. Or you can create a custom object type that gives you that user plus what time the user logged in, and maybe a little more metadata about that transaction in the return object. So again, it’s kind of up to you to design that, but that pattern is really baked into GraphQL.
Drew: This all sounds pretty great, but every technical choice involves trade-offs. What are the downsides of using GraphQL? Are there any scenarios where it’d be a really poor choice?
Eve: I think that the place where a GraphQL might struggle is creating a one-to-one map of-
Eve: … struggle is creating a one-to-one map of tabular data. So let’s say you have, I don’t know, think a database table with all sorts of different fields and, I don’t know, thousands of fields on a specific type, things like that, that type of data can be represented nicely with GraphQL, but sometimes when you run a process to generate a Schema on that data, you’re left with, in a Schema, the same problems that you had in the database, which is maybe too much data that goes beyond what the client actually requires. So I think those places, they’re potentially problems. I’ve talked to folks who have auto-generated Schemas based on their data and it’s become a million line long Schema or something like that, just thousands and thousands of lines of Schema code. And that’s where it becomes a little tricky, like how useful is this as a human readable document?
Eve: Yeah. So any sort of situation where you’re dealing with a client, it is a really nice fit as far as modeling every different type of data, it becomes a little tricky if your data sources too large.
Drew: So it sounds like anywhere where you’re going to carefully curate the responses in the fields and do it more by hand, you can get really powerful results. But if you’re auto-generating stuff because you’ve just got a massive Schema, then maybe it becomes a little unwieldy.
Eve: Yeah. And I think people are listening and disagreeing with me on that because there are good tools for that as well. But I think kind of the place where GraphQL really shines is that step of abstracting logic to the server, giving front end developers the freedom to define their components or their front ends data requirements, and really managing the Schema as a team.
Drew: Is there anything sort of built into the query language to deal with pagination of results, or is that down to a custom implementation as needed?
Eve: Yeah. Pagination, you would build first into the Schema, so you could define pagination for that. There’s a lot of guidelines that have sort of emerged in the community. A good example to look at if you’re newer to GraphQL or not, I look at this all the time, is the GitHub GraphQL API. They’ve basically recreated their API for v4 of their public facing API using GraphQL. So that’s a good spot to kind of look at how is a actual big company using this at scale. A lot of folks have big APIs running, but they don’t make it public to everybody. So pagination is built into that API really nicely and you can return, I don’t know, the first 50 repositories that you’ve ever created, or you can also use cursor based pagination for returning records based on ideas in your data. So cursor based pagination and kind of positional pagination like first, last records, that’s usually how people approach that, but there’s many techniques.
Drew: Are there any big got yous we should know going into using GraphQL? Say I’m about to deploy a new GraphQL installation for my organization, we’re going to build all our new API endpoints using GraphQL going forward. What should I know? Is there anything lurking in the bushes?
Eve: Lurking in the bushes, always with technology, right? I think one of the things that isn’t built into GraphQL, but can be implemented without too much hassle is API security. So for example, you mentioned if I have a huge query, we talked about this with authorization, but it’s also scary to open up an API where someone could just send a huge nested query, friends of friends, friends of friends, friends of friends, down and down the chain. And then you’re basically allowing people to DDoS you with these huge queries. So there’s things that you can set up on the server to limit query depth and query complexity. You can put queries on a safe list. So maybe your front ends, you know what they all are and it’s not a public API. So you only want to let certain queries come over the wire to you. So I would say before rolling that out, that is definitely a possible got you with the GraphQL.
Drew: You do a lot of instruction and training around GraphQL, and you’ve co-written the O’Reilly ’animal’ book with Alex Banks called Learning GraphQL. But you’ve got something new that you’re launching early in 2021, is that right?
Eve: That’s right. So I have been collaborating with egghead.io to create a full stack GraphQL video course. We’re going to build an API and front end for a summer camp, so everything is summer camp themed. And yeah, we’re just going to get into how to work with Apollo server, Apollo client. We will talk about scaling GraphQL APIs with Apollo Federation. We’ll talk about authorization strategies and all sorts of different things. So it’s just kind of collecting the things that I’ve learned from teaching over the past, I don’t know, three or four years GraphQL and putting it into one spot.
Drew: So it’s a video course that… Is it all just self-directed, you can just work your way through at your own pace?
Eve: Yeah, exactly. So it’s a big hefty course so you can work through it at your own pace. Absolutely.
Drew: Oh, that sounds really good. And it’s graphqlworkshop.com, is that right?
Eve: Graphqlworkshop.com, exactly.
Drew: And I’m looking forward to seeing that released because I think that’s something that I might need. So I’ve been learning all about GraphQL. What have you been learning about lately?
Eve: I’ve also been looking into Rust lately. So I’ve been building a lot of Rust Hello Worlds, and figuring out what that is. I don’t know if I know what that is yet, but I have been having fun tinkering around with it.
Drew: If you dear listener, would like to hear more from Eve, you can find her on Twitter where she’s @eveporcello, and you can find out about her work at moonhighway.com. Her GraphQL workshop, discover your path through the GraphQL wilderness, is coming out early in 2021 and can be found at graphqlworkshop.com. Thanks for joining us today, Eve. Do you have any parting words?
Eve: Parting words, have fun with GraphQL, take the plunge, you’ll enjoy it, and thanks so much for having me. I appreciate it.

Are Websites Adding To Consumer’s Health Issues?
Have any of you watched The Social Dilemma yet? For those of you who haven’t see it, here’s a summary of what it’s about:
- People who were instrumental in building the world’s leading social media platforms explain what’s really going on behind the scenes.
- Essentially, social media companies are in the business of selling their users to advertisers and partners.
- So, the social algorithms are programmed to do whatever’s necessary to gather as much user data as possible.
- This often leads to unethical means of grabbing users’ attention and keeping them addicted to scrolling, reading, clicking and so on.
All this has led to an increase in depression, anxiety, lower life satisfaction, distorted realities, compromised relationships and poor health on the part of the consumer.
But let’s be honest. It’s not just social media that sacrifices its users’ wellbeing for its own profitability.
Certain kinds of mobile apps capitalize on users’ addictive tendencies, FOMO and other negative behaviors. But what about websites? Are they responsible, in part, for the deterioration of consumers’ mental and physical wellbeing?
Today, I’m going to show you five ways in which websites are making visitors and customers feel worse and what you can do to help reverse this trend.
Is Your Website Making Its Visitors Feel Sick?
There’s so much toxicity, hate and divisiveness in the world already. The last thing we need is to give people more reason to feel negatively about themselves or towards others.
We are well aware of how dark patterns as well as misuse of visitor data can impact the way people respond to our websites (and later feel about the experience). It’s the whole reason why ethical design is such a critical matter these days.
But what else could your websites be doing that leads users to feel poorly? Let’s have a look:
1. Playing Into Alert Panic with Fake Notifications
Have you ever been watching something on TV or been in a crowded space and heard the all-too-familiar text message chime and reached for your phone?
Of course, you quickly realize the message isn’t for you as the person on the screen or in the crowd does the same thing as you, except they have someone they need to respond to. And you don’t.
We’ve been conditioned to feel disappointed when that notification isn’t for us. Or when it’s not from the person we wanted it to be.
Worse, because we’ve grown so accustomed to that dopamine hit, we’re often overwhelmed with notification alerts — sounds and visual signals — that we’ve activated on nearly every app we use. Facebook. Text. Email. Food delivery apps. Mobile games. Heck, even my meditation app wants to ping me once a day.
Larry Rosen, a psychology professor emeritus at California State University, explains why this is so bad for us:
We’ve trained ourselves, almost like Pavlov’s dogs, to figuratively salivate over what that vibration might mean. If you don’t address the vibrating phone or the beeping text, the signals in your brain that cause anxiety are going to continue to dominate and you’re going to continue feeling uncomfortable until you take care of them.
As a consumer, you’re well aware of the effect that notifications have on people. As web designers, though, what should you do with this information?
Unfortunately, some designers have chosen to add these anxiety-inducing triggers into their websites. Here’s an example from Mobile Monkey:
 Mobile Monkey’s chat widget looks like someone is typing. (Source: Mobile Monkey) (Large preview)
Mobile Monkey’s chat widget looks like someone is typing. (Source: Mobile Monkey) (Large preview)
There are actually two panic triggers in the chat widget:
The first are the three bouncing dots that look like someone is typing a message. The second is the red “1” that appears on the corner of the widget afterwards, resembling the marker you’d see if you had an unread text or email.
Considering I’ve never had a conversation with the chatbot on this site before, this alert does nothing but confuse and annoy me. I came to the site to read about CRO tools, not get interrupted by a chatbot I don’t need.
Another example of this can actually be found on The Social Dilemma’s website:
 The Social Dilemma website uses a notification trigger in the header. (Source: The Social Dilemma) (Large preview)
The Social Dilemma website uses a notification trigger in the header. (Source: The Social Dilemma) (Large preview)
At first, my thought was, “Hypocrites!”. But then I read the entire pop-up and realized it’s actually a brilliant move as it makes their audience hyper aware of how hooked they are to notifications.
Here’s what the grey section beneath the email signup form says:
“WE KNEW YOU’D CLICK THIS!
Notifications like these offer an enticing loop of pleasure that can create an unconscious attachment to our devices.”
This is no different than an actor breaking the fourth wall and looking at the camera to address the audience. While it works for the film’s website — since its whole message is for consumers to break free from this kind of digital dependence — it’s just going to cause harm when used on other sites.
2. Deceiving Customers With Dishonest Photos
Have you ever noticed that social media has become a sort of “second life” for some people?
The most obvious example of this are influencers. They take pictures of their fancy homes, luxurious vacations and expensive clothes. But we’re learning more and more that this isn’t the reality of their day-to-day lives and that the highly staged photos are designed to manipulate fans into buying the products they promote.
But it’s not just influencers who lie on social media. Many of the people we know fall prey to this — only putting out the idealized photos of themselves, their families and their lives.
An article written by Dr. Cortney S. Warren for Psychology Today recaps the results of a number of studies on the correlation between social media and lying:
- 67% of daters have lied about their weight.
- 43% of men have made up facts about themselves and/or their lives.
- 32% of people only shared non-boring aspects of their lives on social media.
- 14% said they make themselves appear more physically active on social.
- Only 18% of men and 19% of women said their Facebook pages were completely accurate.
Warren explains how these lies — while they make the liar feel better about themselves — actually do a lot of harm for everyone exposed to them:
To make matters more complicated, when we internally believe that what we see in social media is true and relevant to us, we are more likely to compare ourselves to it in an internal effort to evaluate ourselves against those around us (e.g., regarding our looks, wealth, significant other, family, etc.). As we do this against the idealized images and unreasonably positive life accounts that tend to permeate social media, we are likely to feel more poorly about ourselves and our lives.
Unfortunately, this is something that brands do, too, when they use inauthentic, idealized and doctored photos on their websites. Take, for instance, the example of McDonald’s. This is how its famous McRib is portrayed on its website:

Have any of you ever gotten a sandwich from McDonald’s or any fast food joint that looked that impeccable? Don’t get me wrong. I eat fast food more often than I’d like to admit. But I don’t lie to myself about what I’m about to find in my takeout bag. And that photo right there is definitely not what I’m expecting.
It’s irresponsible of any business to set such unrealistic expectations from the start. This can happen with all kinds of brands, too. For instance, travel companies that make their properties look fancier than they really are or medical facilities that look well-organized and clean when they’re not.
And what about retail and fashion companies that use super-skinny girls to show off their clothing? Not only do those photos lead to frustration when a customer can’t fit into something they bought, they’re likely to blame themselves for being too “fat” or “ugly” or whatever kind of self-hate they decide to inflict on themselves.
If you can’t be honest in your photos, then what your website sells is a lie. And you have to expect the deception to come at a price.
3. Bombarding Visitors with Addictive Content
Social media platforms and their algorithms are designed to keep users logged in and engaged.
If a user were to slow down while scrolling through their feed, for example, the algorithm would run a calculation to determine what might suck them back in. It could be:
- A “Suggested for You” post featuring puppies playing in snow,
- A notification that a close friend just posted something for the first time in awhile,
- An ad for a product the user was looking at on Amazon a few days back.
We’re living in a time of information overload and social media platforms are very good at taking advantage of it. By constantly throwing something new into our field of vision, it becomes harder and harder to pull ourselves away. What’s more, when we’re feeling unmotivated or unproductive, we know exactly where to go to drown ourselves in distractions.
It’s gotten worse during the pandemic, too. As research scientist Mesfin Bekalu explains:
As humans we have a ‘natural’ tendency to pay more attention to negative news.
Addictions specialist Dr. Paul L. Hokemeyer elaborates:
A person who doomscrolls found at some point in the trajectory of their disorder that searching online for information on disturbing events gave them comfort. It gave them a sense of control over their lives and re-engaged their intellect. But while they thought they were being soothed by facts, what they were really doing was hyperactivating their emotional reactivity.
It’s not just scientists and health professionals who are aware of this. Social media algorithms are, too. And because they’re programmed to manipulate users with content that’ll make them want to keep reading and engaging, guess what people’s feeds are full of?
One of the benefits of building a website for brands is to get consumers away from the chatter, distractions and negativity that thrive on social media platforms. That doesn’t mean you’re free to bombard your visitors with content that exploits their addictive tendencies though.
And, yet, it happens. This, for instance, is what I saw when I clicked on a link to an article on the Small Business Trends website:
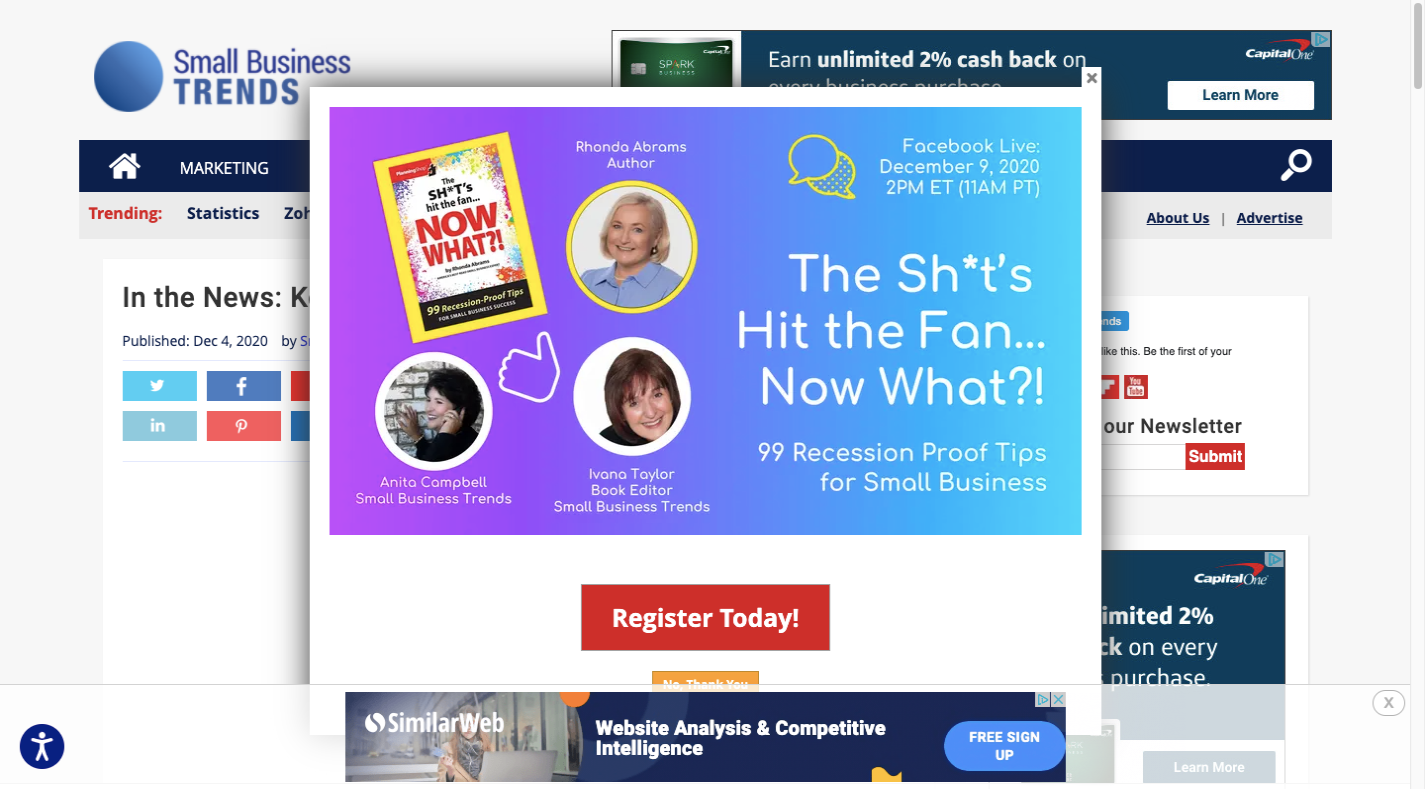
In just my first second on the site, I saw:
- A pop-up reminding me about the pandemic and recession,
- An ad for Similar Web sitting on top of the area of the pop-up where I could say “No Thank You”,
- A newsletter subscription form on the right,
- Ads for Capital One in the header and sidebar.
I see zero content (the title isn’t even fully visible) and I’m overwhelmed with ads — one of which hooks into the anxiety I’m already feeling about the pandemic. I’m sure I’m not the only person who’d feel the same way looking at this site.
It’s not just an overwhelming amount of ads that make visitors feel uneasy or, worse, compel them to explore each of the distractions before actually getting to the content.
For example, there are websites that display promotional videos, but then don’t allow visitors to escape them, as Fast Company does in its sidebar:
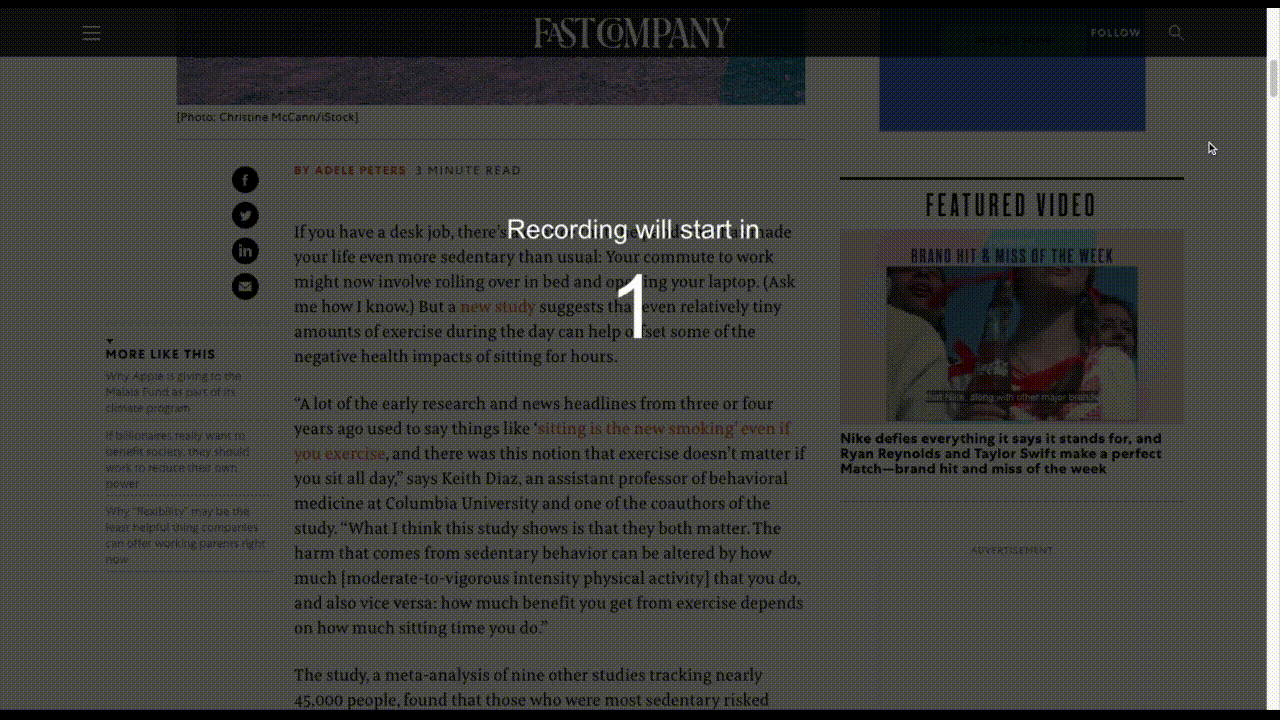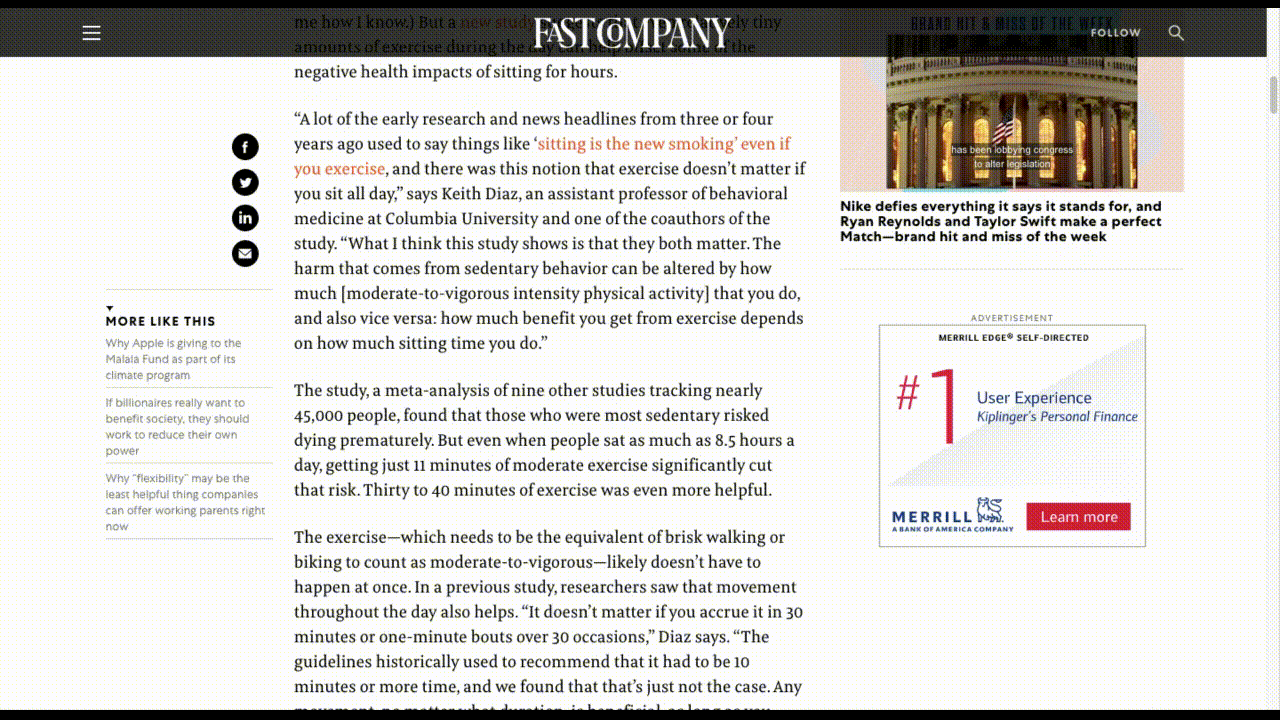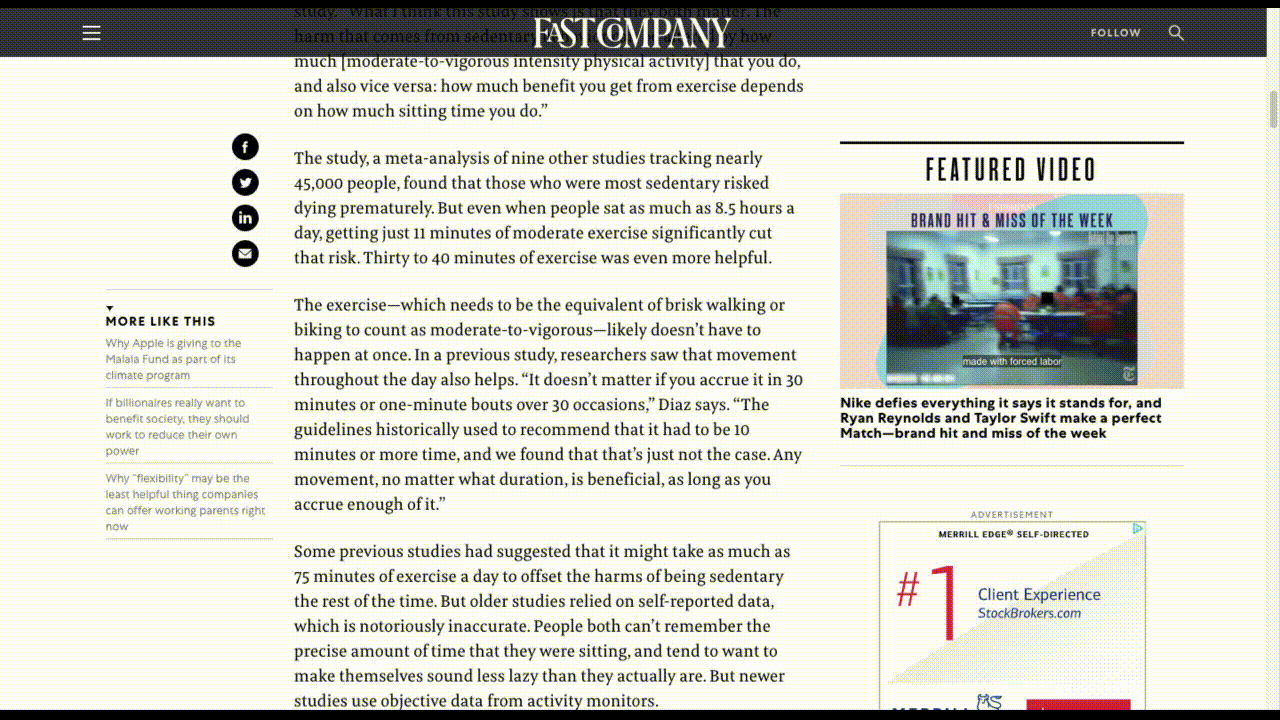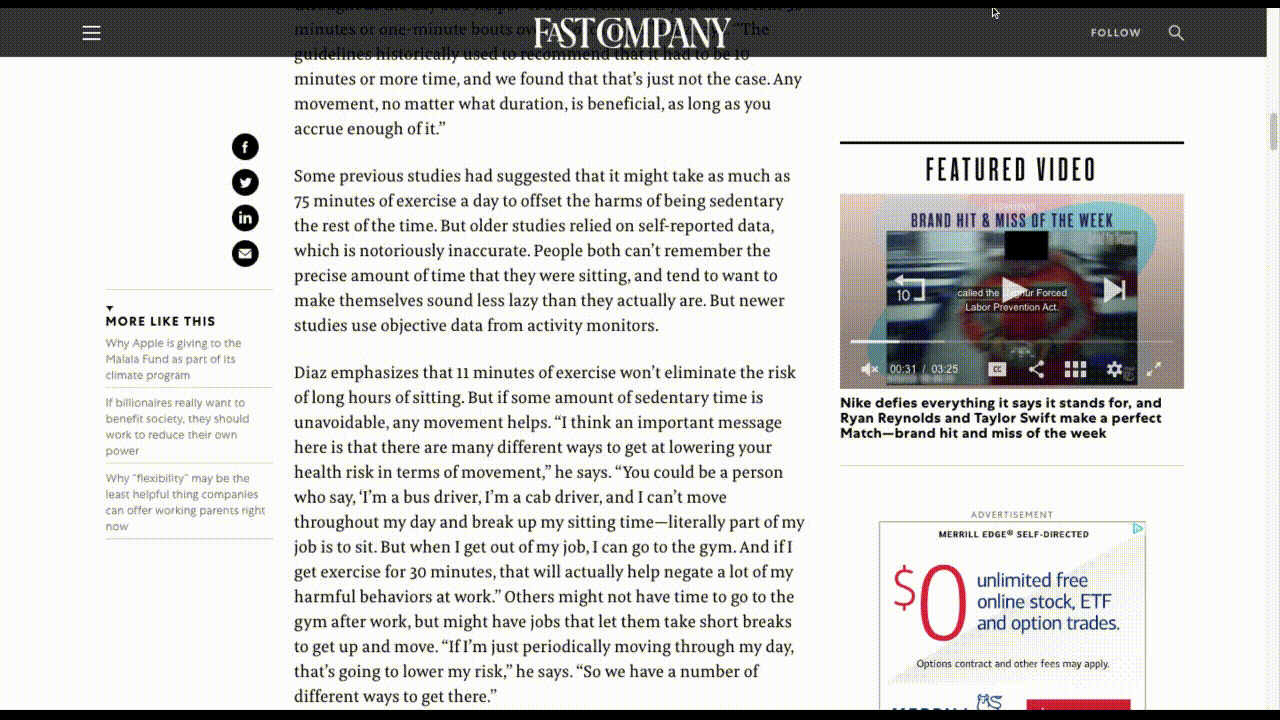 Fast Company’s video ad follows readers as they move down the page. (Source: Fast Company) (Large preview)
Fast Company’s video ad follows readers as they move down the page. (Source: Fast Company) (Large preview)
There’s no sound unless the visitor triggers it, but it doesn’t matter. The fact that the video is glued to the sidebar, auto-plays and shows the captions makes it an inescapable distraction.
Sites that use an endless scroll are another example of brands exploiting consumers’ addictive tendencies. Entrepreneur has an endless scroll that ensures that visitors will find more content to read… if only they keep scrolling and scrolling and scrolling:
 Entrepreneur’s internal pages include a never-ending scroll. (Source: Entrepreneur) (Large preview)
Entrepreneur’s internal pages include a never-ending scroll. (Source: Entrepreneur) (Large preview)
Endless scrolling pages are a lot like going to an all-you-can-eat buffet or somewhere that offers “bottomless bowls” or “never-ending refills”. You know your customers are going to gorge themselves. And while they might enjoy it at the time, they’re going to walk away from the experience feeling mighty ill and probably a little ashamed with themselves for throwing away all that time, too.
Another thing this site does that’s worrisome is that it displays tracking banner ads.
You can barely see it in the video above, but the top of the page has a big ad for Flatfile, which is something I’ve been writing about for the last few weeks. So, before I could even focus on the content, I started stressing out about the state of my current projects.
While that exact response isn’t what the ad was meant to elicit, it’s supposed to stir up some type of anxiety or FOMO for a purchase not completed. For consumers that are struggling with a shopping addiction or outlandish debt, your website could realistically become a vehicle that feeds into it.
Wrap-Up
I know it’s your job to build websites that attract visitors, encourage those visitors to engage with the sites and eventually turn the engagement into conversions.
But if you want to do your part in designing more humane digital experiences, then it’s time to stop exploiting your audience’s vulnerabilities.
You can still take what you know about human psychology and use it to design attractive, friction-free and user-first experiences without manipulation and deceit.
Trust me. With the backlash social media platforms face (like after the Cambridge Analytica scandal), the number of people who quit them every year and now a high profile movie like The Social Dilemma, consumers are waking up. And it’s not just going to be Facebook they abandon when they realize how their thoughts and actions were controlled by a piece of technology and the people who built it.

15 Best Digital Marketing Blogs Filled With Valuable Advice [2020]
If you are searching for the top SEO and digital marketing blogs filled with the best advice then you have come to the right place.
Here, I am listing the top digital marketing blogs that are worth reading if you are a beginner or advanced marketer.
Let’s start!
15 Best Digital Marketing Blogs
1. SEMRush
Popularly known as the top digital marketing tools for industry, SEMRush has also marked its presence as the best industry blog provider.
It has left no stone unturned to cover every possible aspect of digital marketing.
From website optimization to content marketing, link building to brand management, and everything in between is covered at one single platform.
Some of the topics are even brand specific, like Amazon SEO.
Readers can grasp knowledge from various ways like blogs, news, opinion, case studies, tips, and more, all written by industry experts and specialists.
Interestingly, readers have a choice of six different languages as the site is multilingual.
People love SEMRush for fresh and valuable content on digital marketing.
2. SEO Sandwitch Blog
SEO Sandwitch is the best SEO blog for beginners.
It contains easy to read tutorials on almost every digital marketing topic that you can think of.
This blog is run by SEO expert Joydeep Bhattacharya who has been working on understanding search algorithms since 2009.
All the articles in the blog are written by Joydeep and they are worth reading.
Content is filled with practical examples that are hard to find on other blogs.
You will certainly find something new if you start reading this blog.
For SEO and digital marketing beginners, this blog is worth reading.
3. Buffer Blog
You need to keep up with the current social media marketing updates, especially when digital marketing is placing so much importance on social media.
Buffer blog is the best site to know everything going around social media.
It is a huge source of social media marketing content, along with online marketing and content marketing.
The content focuses on helping marketers build the brand through social media platforms using different techniques and proven methodologies.
Readers bookmark this site to get the latest updates on fresh branding techniques and ideas.
4. Search Engine Watch
Dedicated solely to search engines, the blog site is a pool of knowledge and information about the search engines.
Search Engine Watch offers all the insights relating to SEM, SEO, and paid search in the form of articles, analysis, news, and tips.
Apart from the content provided here, readers even get benefited from the informative comment section where visitors discuss the topic with the author.
Using such valuable content, site owners are succeeding in improving their online visibility.
Certainly, this site is the all-time favorite of marketers and site owners looking to rank up their site in the search results.
This site is mostly bookmarked to know about new SEM and SEO trends, and PPC marketing tips.
5. Google Webmaster Central Blog
What can be the better source to know the technicalities to index your site in Google than Google itself?
Google Webmaster Central blog is packed with its official news on topics related to crawling and indexing sites.
You will get a plethora of blogs here that will give you ideas to improve your strategies for better site ranking.
The blogs are highly technical in terms and intended to target the expert audience, so beginners may not find it easy to understand.
Needless to say, why marketers do not forget to check out this site every day.
6. MarketingProfs
If you are looking for a good source of how-to articles on the latest marketing tactics, tips, and strategies, MarketingProf is an appropriate site.
Huge stock of blogs on different topics has been covered for the best reader experience.
From ad copy to B2B marketing, branding to content marketing, you can find an array of blogs to learn about marketing and related aspects.
The content is focused entirely on sharing top marketing tips and strategies.
The site is updated with fresh content regularly, which means there is a great opportunity to grab knowledge and watch its practical use.
7. The Convince & Convert Blog
When your target is not just to soak up tips and ideas, but also to understand the core of the idea, look no further than Convince & Convert blog.
This blog specializes in content marketing and it excels in what it publishes.
It is a content marketing consultant and therefore they have genuine and practical knowledge to share.
It is a gold mine for those who want to learn more about social media, influencer marketing, word of mouth, and customer experience along with content marketing.
Every piece of content is a dose of insights marketers need to stay on the top.
Plus, if you subscribe to its newsletters you will get some fun surprises.
8. Top Rank Marketing
Top Rank is one of the leading digital marketing service providers, but it also serves as a fine source of data-driven marketing insights.
It covers selective topics like influencer marketing, content marketing, and search marketing, but, each topic is covered extensively.
What you get here is exclusive and offered by industry experts.
The publishers have the knack of boosting visibility, attract and retain customers, and attain search engine ranking.
Naturally, they are the best in providing industry trends and tips and tricks of the digital marketing industry.
Readers bookmark this site to learn more about Influencer, content, and search marketing.
9. Smart Insights Blog
More popular as a marketing tool provider, Smart Insights is also known for its extraordinary blog content.
You will find insights on various topics including marketing, optimization, advertising, etc.
Apart from these, readers can also learn more about Google Analytics and lead generation, insights shared by industry experts.
Its list of categories includes many untouched topics by several blog sites, such as you can even get tips on persuasion marketing, market place analysis, localization, etc.
This blog is often followed for the content blogs on interesting and highly needed topics.
10. Yoast
Yoast holds a specialty in blog posts on topics like Content SEO, Technical SEO, Analytics, eCommerce, and WordPress.
Both beginners and experts can have engaging and informative content to read.
While beginners can learn basics, experts can discover advanced tips to improve their SEO skills.
Using the cutting-edge strategies and guides on SEO and conversion, marketers can take advantage to rank their sites.
It gives additional benefits to its new visitors.
You get an option to download free plugins and new features.
Besides, new learners can enlighten themselves with a free beginner’s course.
11. BuzzSumo
Everything you want to know about content marketing, influencer marketing, digital PR, and video marketing, you will find at BuzzSumo.
It provides unique, informative, and practically useful blogs one after another that any inquisitive readers would look for.
If you are looking to create viral content, BuzzSumo is the right destination to reach.
Using top experts’ tactics and plans, you can turn ordinary content into a viral one.
Readers love to check out new ideas on viral content creation.
12. Unbounce
Unbounce is given the credit of being an expert in providing the industry best conversion rate optimization tips.
It helps build an effective and lead generating landing page using its insight on landing page optimization.
So, this is heaven for marketers looking to attract some traffic on their site.
Also, it offers news and some excellent articles on pay per click and online marketing.
Unbounce is an exceptional blog to learn the core ideas behind a successful landing page creation.
13. Think with Google
For expertise in marketing, you need to know the advanced level marketing strategies.
Think with Google, helps you get the industry-standard expert category tips and ideas to attain the level you wish.
You can read a lot about programmatic advertising, omnichannel, and measurement.
It is packed with high standard marketing topics like consumer insights, original research, and data visualizations.
So, you can dig into new insights and learn about how branding techniques.
14. Social Media Examiner
As its name reflects, Social Media Examiner has a niche in social media marketing.
It is the best blog to look for social media insights.
You can find almost everything you need to know about the marketing curves in social media like how-to articles, weekly news, expert interviews, tools, and research.
Video tutorials on Facebook ads, Instagram ads, LinkedIn ads, Instagram Organic marketing, and Tiktok, are also available.
It also produces a 10-minute daily podcast on marketing tips for using social media.
Overall, it curates content that is of exceptionally good value.
Marketers loving this blog for its high-value posts contributed regularly.
15. Social Media Today
Again, another extraordinary blog for social media marketers to follow.
It writes about every development noticed in the social media industry.
You can get content to read about any possible topic on social media marketing posted by a massive network of regular contributors.
With a huge number of blogs on news and tips, it is an impressive library of social media marketing content to learn the art of taking maximum advantage of the available platforms.
It is a great source to stay updated with the algorithm, latest features, and releases in social media, which is very useful to plan a strategy.
Besides, it offers many ways to implement your strategy more effectively.
Tips by top social media specialists, social media marketing tools, and opinion articles from expert marketers, are a few examples.
The Bottom Line
Now, when you have all the required lists of the digital marketing blogs, you can pick those that go well with your interests.
You can bookmark these digital marketing blogs, or you can also subscribe to email updates so that you never miss a chance to soak up anything they have to offer.
The post 15 Best Digital Marketing Blogs Filled With Valuable Advice [2020] appeared first on SEO Basics.
![How to Sustain Influencer Marketing on Social Media Platform [2020]](https://v3n6x2i7.rocketcdn.me/wp-content/uploads/choose-the-right-social-media-platform-cOZrLG-1170x700.jpeg)
How to Sustain Influencer Marketing on Social Media Platform [2020]
In today’s post, I’m going to show you how to sustain influencer marketing on the social media platform.
After reading this complete post, you will be able to understand how to use influencer marketing on the social media platform for your project.
So let’s start without further ado.
The term ‘influencer marketing’ has turned into the most commonly used term in social media marketing.
Social media platforms have transformed into e-commerce platforms where brand promotions, purchases, and other commercial activities take place.
It is predicted that globally renowned brands will have 70% of their sales through social media platforms by 2022.
Thus, social media platforms are evolving into the epicenter of sales and marketing.
Meanwhile, ‘influencer marketing’ has become the most sought after strategy to convince people to buy products on these platforms.
If you choose to go with influencer marketing to promote your business, note the factors that are given below, which avail you of a huge benefit.
1. Choose The Right Social Media Platform
Influencer marketing is widely regarded as a successful marketing strategy.
You can turn it into a flop if you hire an influencer from a social platform that is irrelevant to your business.
The foremost essential factor that you should consider in influencer marketing is finding the right platform that suits your business.
Conduct sufficient research to find at which social media platform most of your target audience is present and where you could find your target audience easily.
Trollishly is a well-known service provider that will help you to find your prospects effortlessly on any social media platform.
Five years back, Facebook and Instagram are the commonly used social platforms for promotions.
Brands cannot look further beyond these platforms because they were the only social application with a global presence.
But things are different now.
We have a handful of social apps with a consistent user base.
For instance, if your product is for teens, you can go with TikTok and Snapchat.
These platforms have teens as their prominent user base.
If you are looking to endorse beauty and fashion products, it is better to go with Instagram, where 58% are female, and 42% are male.
If you are into the video gaming industry, you can try ‘Twitch,’ the platform that is completely dedicated to avid gamers.
Thus, people are spread across various platforms based on their interests.
So, have in-depth knowledge about a social platform such as user base and demographics before hiring an influencer.
2. Be Wise in Choosing Your Influencers
You have to consider multiple factors before choosing an influencer.
Let me bring out some of the points you should consider before choosing an influencer.
(i) Know About His Userbase
Having a large number of followers alone is not sufficient in choosing an influencer.
If you pay a large sum of money to an influencer who has a huge fan following, chances are there for you to have a very fewer sales value compared to the money you spent on him.
The reason behind this is that the influencer could have a very meager of your target audience as followers.
So, before collaborating with an influencer, ensure whether he has a consistent number of your target audience as followers.
(ii) Ensure Whether The Influencer Fits-in With You
Confirm whether the influencer you choose correlates with the characteristics of your brand.
You are going to ideate concepts and create promotional videos that would revolve around the influencer.
So, the influencer should ideally fit in those videos.
Let me give you a simple example.
Just assume that you are looking out to endorse muscle grower powder through a social media platform.
Some people rose to fame on social platforms by showcasing their singing ability.
If you collaborate with one such person who is underweight or oversized, people will not be convinced to buy your muscle growth powder.
At the same time, if you collaborate with any athlete or an acrobat, it will be much easier to convince people.
Moreover, ideating concepts using them to create promotional videos will be much easier for you.
So, try to join hands with the influencer who could align with your ‘brand tone’.
3. Take Advantages of Videos
Today, all the major social platforms have turned into video-dominant platforms.
Facebook has a section that is entirely dedicated to videos, and Instagram has its very own IGTV.
TikTok is a complete video platform.
People spend a larger part of their time on social platforms by watching videos.
They show less interest in scrolling through the images or posts that are rich in words.
It is predicted that 87% of online content will be in the form of videos by 2022.
So, focus on creating video for your brand by using the influencer.
Moreover, the video can be used across multiple social platforms and even on television and OTT platforms.
(i) Make a Note of Ephemeral Content
Ephemeral content is the next big thing in social media marketing.
These are short-duration videos that will disappear after 24 hours or at a particular time.
The engagement rate of these ephemeral videos is consistently increasing because it will last only for 10-15 seconds.
It won’t even long for even a minute.
So, people always feel free to watch these videos as they consume much of their time.
A recent study showed that Instagram stories have a 4x higher engagement rate than standard posts.
So, create short-duration videos with the influencers for your brand.
Create such videos frequently at least three to four times a week and post them on the stories section of the influencer account.
Such a measure will increase the visibility of your product.
4. Influencers ‘The Effective Tool’ for Hashtag Challenges
Hashtag challenges are always considered as one of successful marketing campaign tactics as it has the potential of elevating the reach of a brand at a quick pace.
Usually, in a hashtag challenge, people are asked to perform a particular task.
If the ‘task’ is intriguing, many people will come forward to participate in it, which will turn the campaign into a massive hit.
If hashtag challenges are introduced using influencers, many people will come to know about it instantly.
For instance, Samsung made its smartphone launch Galaxy A popular in Germany by collaborating with famous TikTok influencers Selina Mour and Falco Punch.
As part of the campaign, people are instructed to draw the letter ‘A’ in their hand palm and teleport it to another person’s palm through the phone’s transition effects.
The campaign was ideated in such a way to communicate the product’s message ‘communicate with your friends’.
It was received well among the people since the videos that are created for the hashtag challenge received around 30 million views.
So, influencers can be utilized as a medium to launch hashtag challenges.
5. Beware of the Budget
Due to its increasing importance among marketers, influencer marketing has turned into one of the costliest means of marketing.
In recent times, many influencers are charging a hefty price.
Just enrolling an influencer for your brand promotion will not do wonders and uplift your sales.
So, ensure whether the influencer is worth the money he is demanding from you.
At least, you should achieve the sales profit of double the money you spent on the influencers.
So, be cautious about the money you spend on them.
Let us look at how the influencers are categorized based on the followers they have:
Nano Influencers– 1K – 10K followers
Micro-Influencers– 10K – 50K followers
Mid-Tier Influencers– 50K – 500K followers
Macro Influencers– 500K – 1M followers
Mega Influencers– 1 Million and above
(i) Test The Waters Through Micro-Influencers
If you are doubtful about the way influencer marketing will work, join hands with micro-influencers who have 10K-50K followers.
They charge a meager amount when compared with macro or mega influencers.
It would help you to gain deep insights and practical knowledge into the way influencer marketing works.
Moreover, tying up with micro-influencers is considered as an efficient measure in recent times.
Renowned global brands like Adidas and Dairy Milk have followed this strategy and achieved impressive results.
One of the common characteristics of micro-influencers is that they will have a strong follower base in a particular region.
If you feel that the people in Louisiana do not know your product, check out for the influencers who are famous and collaborate with them.
6. Collaborate With An Influencer For A Long-Time
Today influencers are enjoying a massive fan-following as the same that of traditional celebrities.
So, fix an influencer and make him the face of your brand.
Stay with him for at least 3 or 4 years.
Changing influencers constantly for your brand will not be an ideal move.
Moreover, you have to ideate new concepts in accordance with the characteristics of the influencers.
Chances are there for the new influencer endorsing your brand may not be accepted by the people.
So, collaborate with an influencer for the long term.
Final Words
A recent survey shows that 70% of teens find influencers more credible than traditional celebrities.
Many influencers have garnered a good name among their followers by delivering intriguing content and interacting with them consistently.
So, businesses are looking to use these influencers as a medium to reach out to people and to drive people towards them.
It is expected that influencer marketing might reach $13 billion in worth by 2023.
Since the demand for influencers is consistently growing, don’t rush up and choose someone randomly.
Keep the factors in mind that are given by me and pick an influencer accordingly to take your business to the next level.
The post How to Sustain Influencer Marketing on Social Media Platform [2020] appeared first on SEO Basics.

9 Tips and Secrets of Sustaining SEO Agency in 2020
In today’s post, you will learn about 9 tips and secrets of sustaining SEO agency in 2020.
So let’s start.
The year 2020 brings a lot of drastic modifications in aspects of life, especially in business.
It’s difficult to sustain in the business when the whole world is growing through the pandemic of COVID-19.
To deal with all the issues in business your company demands the best practices to be ahead in the business.
It is important to advertise your business right to reach the intended audience of your channel.
You have to make a little extra effort to keep your business in the right place.
SEO is the manner of leveraging particular phrases, keywords, and some essential variables.
These are set on the website to boost the tangible ranking of the website on the main search engines, like, Google.
More than 200 well-known variables that influence SEO and every search engine ranking website somewhat differently, according to the particular type of search engine measures being used on the platform.
This is the reason that it is essential to consider that specific variable that can change the website’s organic ranking.
For that, you need the best SEO agency.
The main motive of the SEO agency is to produce and write great content and optimize it in a better way to search using SEO best practices.
But nowadays, SEO agencies are suffering a lot in business!!
Keeping up the SEO agency is a bit difficult.
The trends and tactics have changed completely now.
The companies who are booming are in the business and have to deal with complexities like economic crises, reducing staff, etc.
Budget is the most prominent issue among all problems.
Many businesses are not stable these days as companies have to cut the cost in the different dimensions to run the companies.
So to be successful in the long run your SEO agency demands new approaches to be ahead in 2020.
Here we are going to review the different tips and secrets to support an SEO agency in 2020.
Smart Strategies for Sustaining SEO Agency in 2020
1. Be Connected to Your Audience
In this crucial time, it is important to be more active online and connected to your audience.
Social media is the one platform that can take your business to peaks.
So, with the tremendous change in life, social media becomes the largest platform to connect your business effortlessly.
It is the best marketing tool for your SEO agency.
However, you can integrate your business with a social platform like Instagram, Facebook, Twitter, etc. that help to engage new users.
All you have to do is to post regularly and update your customers and execute consistently to make your venture a great success.
2. Prioritize Business Tasks
In hundreds of tasks in business, it’s difficult to sort each and everything.
To categorize all the things appropriately is much needed.
Because sorting avoids the wastage as well as extra expenditure.

It will reduce the cost of your business and boost up the sales.
You can divide the tasks into different sections and in different groups.
This will take your business into another level.
It also reduces the stress of the staff.
3. Make a Strategy
After clearly defining the concepts, make a plan for a successful company.
The success or failure depends upon the right approach.
For a useful and informative approach, everything must be interlinked.
There are some facts that need to be considered for creating a strategy are:
- Make sure that you are precise and clear in your language.
- Set the time for your work.
- Must answer all the questions like what, why, where, when, and how before further consideration.
- Track the method and measure the performance and check whether your goals are achievable.
- Analyze the relevancy, whether it meets your needs.
4. Build a Prototype
After identifying all the features, hiring a team is important to build a prototype.
This is the process of taking your ideas and turning them into great business with some basic functionality.
A prototype is quite easier to sell your idea to likely buyers who can now truly view the actual benefits instead of just visualizing or reading the description of the product.
You can also share the model with beta testers and get an idea of what changes are required to make the business a great success.
5. Better Analysis Tool
As 2020 is already in the rearview mirror, it is high time to brainstorm about the marketing strategy.
It is prudent to take a step back and reflect on the crucial factors that played a crucial role in the success of marketing campaigns.
Now, the burden is on you to maintain the strength and evolve the digital strategies.
Besides all these efforts, it is vital to understand the pace at which contemporary technology is evolving.
You can do it with a better analysis tool.
Regular updates and induction of new techniques along with changes in the algorithms are some mainstream changes now.
Naturally, digital marketing companies are thriving to match and maintain their tactics in harmony.
Website analytics helps in laser focus tracking the advertising ROI.
Track the business goals, website conversions, and activities of the users on your website.
Moreover, comprehensively understand your customers.
Every report and data can be customized and analytics data is in the seamless and streamlined display.
In a nutshell, maximize the reach of your online business with smart work with tools like Google Analytics.
6. Improve the Business Model
Other than prioritizing the customer retention, you must centralize the attention to your endurance.
Indeed, the condition is not aggravating for all, and you might also be holding the pressure.
Here, we advise you to select the white label Search Engine Optimization to improve the business model in 2020.
The best one can appropriately assist you to get the service quality to the other level, with the refined outcomes for every customer.
Also, it assuredly gets more accessible to retain customers and to get the best results.
Collaborating with the reseller shows the best way to grow in the future since you have a more active way of doing the business.
7. Encourage Them to Fix Priorities
In times of crisis, it is the turn to show the support and it is where the SEO agencies have to do for the customers in 2020.
The industries such as travel and hospitality need to hit and you need to do everything to allow the customers to endure.
You can assist them to prioritize the marketing forces to improve their efforts to those to provide good sales with fewer spendings and the most active time span.
Cutting back and pausing on the work even have some idea as it might have fewer profits for the business.
But, you cannot lose the customers in every case if they abandon to make it from the crisis.
On the other hand, you cannot gain potential customers if you assist them at this juncture.
8. Increase Brand Authority in 2020
Brands have now become smarter.
And, they have understood the significance of making the quality content to delight the customers.
The intent oriented content is definitely a great initiate for making to improve the search engine game in 2020.
Even though, to be on the top, you have to gain the trust of potential customers even before they visit your website.

Acquiring reviews or ratings from the customers who have taken the services is also the best way to implement this.
Moreover, the search engine rankings also have a major role to play in improving the Search Engine Results in Page clickability.
When the great search engine ranking is combined with the brand authority, then, the business will definitely touch the new heaps in 2020.
Despite that, with the continuous improvement in the service quality, you can get revel in the online reputation management (ORM) for the optimization of the website for search engines in 2020.
9. Post Interactive Content
Content and blogging are cardinal aspects of search engine optimization.
They play a pivotal role in deciding an overall ranking of your website.
The main use of keywords is that it helps in improving the overall ranking.
By producing high-quality articles, you can increase your business authority in a particular niche.
The trick is to write SEO friendly content.
Visually appealing content and using social media handles like Facebook, Instagram can be a booster in your strategy.
Wrapping Up
Above we have discussed some of the best tips and secrets of sustaining the SEO Agency in 2020.
The marketing strategies help in your business.
You can instantly boost your business with better tactics.
A good approach can give great help to your business and automatically increase revenue.
Positively, this article will give you the best knowledge and more benefits.
Your suggestions and queries are welcome, so feel free to ask in the comment section below.
Thank you for reading!!
The post 9 Tips and Secrets of Sustaining SEO Agency in 2020 appeared first on SEO Basics.

An Ultimate Guide to SEO for Dropshipping Business in 2020
In today’s post, I’m going to show you how to do SEO for dropshipping business and get higher rankings in Google SERPs.
After reading this complete post, you will be able to understand how to increase organic traffic by implementing the below-mentioned SEO tips into your dropshipping business.
So let’s start without further ado.
As a dropshipping store owner, one thing you need to know is how to use search engine optimization (SEO) for your company before creating your website.
Dropshipping sites have a specific set of SEO challenges to conquer as opposed to stores that carry their own inventory, so it’s crucial you know how to use SEO for dropshipping.
This beginner’s dropshipping SEO guide is designed for people new to that framework.
It is also targeted to those who work in the dropshipping industry or have stores dependent on data feeds.
Everyone pursuing SEO for dropshipping would receive invaluable advice to increase the amount of organic traffic that their store or website receives.
SEO consists of several different interrelated activities, and only works best if you account for them all.
One crucial feature of SEO is the integration into the material of carefully researched keywords.
SEO For Dropshipping – Key Principles
1. Keyword Counts
The length of content on each page of your website plays a crucial role in dropshipping SEO rankings.
The more words on your website page you have, the better it is for search engines to grasp what your website is all about.
In addition, this is one of the most basic and well-recognized aspects of understanding how to conduct SEO.

The first element of using keywords in your web text is to use them in an optimal ratio with the total volume of content.
That is why marketers recommend that you include at least 350 to 500 words per page.
Keep in mind that your customer wants the content to be useful so they can have a positive experience while visiting your shop.
Also, the content should look natural.
Try to think carefully about the content that you provide on your website.
If you’re looking to have more content on a category page, consider adding content to welcome visitors in the shape of an intro.
On the other hand, if it is a product page, you can add content that explains each product in detail.
2. H1 Tags
The H1 tag is like a book title.
It’s one of the first items that explain what a user can find on your web page when the search engines read it.
SEO dropshipping optimization highly values the use of H1 tags appropriately.
If it is a product section, then the product title will be your H1 tag.
If it is a category, it is going to be the name of the category.
Consider using modifiers such as best, top, buy, etc.
Do not overdo it with the keywords in your H1 tags much, like the image names and alt tags.
This may be viewed by Google as spam.
You can also get a penalty for over-optimization if you do.
This is a ‘keyword stuffing’ portrayal.
3. Title Tags
Title tags are necessary at dropshipping SEO.
When someone uses a search engine, the title tag is what appears in the results of the search.
The title tag must be less than 55 characters.
Title tags are also critical to the terms of the search for which you want to rank while enabling others to click on it.
The title tag is also what is displayed from the bookmarks tab when a person bookmarks a given page and when they use the browser buttons at the top left corner of the screen as they move forward and backward.
In addition, the title tag is also what appears in the browser history of one person.
This is why it’s so essential with so many uses that you create the title tag descriptive, brief, and user-friendly.
4. Meta Descriptions
Another essential concept of SEO for dropshipping is the Meta description.
By using a search engine, meta descriptions will appear directly below the title tag.
Retain between 120 Characters and 155 Characters.
They should be meaningful and explain what the person who clicks through can find on the website.
If you nail that aspect of our beginner’s dropshipping SEO guide, you’re going to really stand out from the crowd.
Particularly when it comes to dropshipping SEO, make sure that your description tags promote clicks.
Give the person a reason to get your site clicked through by letting them know what they’ll find through your meta summary.
You could do this by putting in the meta description information about a great price, a how-to guide, or a list of focus-grabbing.
5. Internal Linking
Linking is another essential part of understanding how to use dropshipping SEO.
Internal links are links pointing from one page of your site to the next.
Backlinks and external links are quite different from internal linking.
Internal links should always have ‘do follow’ HTML tags.
In this way, you are signaling crawlers for the search engine website to navigate to the page it connects to, which gives ranking power from that page to the next.

In other words, the internal links can be used to tell the search engines which pages to list.
Internal linking also helps your clients explore other sites on your website.
In SEO for dropshipping, internal links show the pages you would like to rank for similar keywords in the search engines.
They also help categorize the site to the search engines and improve the authority of the domain.
If you have an impressive blog post or infographic page with a lot of high-level authority, high-quality backlinks, adding a similar internal link to a specific keyword will enable the page you link to rank better.
Internal links are of immense importance to Dropshipping SEO.
Where needed and relevant, add them and be sure not to overuse it.
This way, you can strike the right balance without making your content appear unrealistic to raise rankings.
6. Backlinks
Backlinks play a significant role when learning how to SEO for dropshipping in bringing the traffic back to your site.
This is because backlinks are links that point back to yours from another website.
They are the most important means, combined with the content on your website, by which you can get a website to rank high in search engines.
Search engines take extreme measures to ensure the backlinks to a website are organic.
But don’t buy backlinks to increase your domain authority, as it will penalize your site.
Getting too many rich or abnormal backlinks on keywords will result in penalties.
Don’t make too many of them up.
Keep it less than 20 percent of your total link description, maybe just 10 percent.
7. External Links
Another critical aspect of the SEO for dropshipping is understanding how external links fit into the system.
External links carry a user to websites other than your own when clicking on them.
When you own an eCommerce shop, do provide external links in blog posts.
Includes valid reasons for adding an external link to a blog post when you source a site or discuss something necessary to your audience.
Until inserting any external link, first, read the instructions for Google do-follow vs. no-follow links.
8. Dropshipping SEO Strategy Sitemap
Learning how to use SEO to build a sitemap for your website is an essential SEO for dropshipping guidelines.
A sitemap is fundamentally just a listing of all the pages that Google should be aware of on your website.
They are subdivided from your website’s highest level pages and include categories, subcategories, and product pages.
With links and XML feeds, you can create sitemaps in multiple ways, among other simple methods.
Be sure that you do not have a redirect 404 or 301 and the pages on your sitemap.
9. Datafeeds
If you’re dropshipping, you are likely to draw a lot of product information from descriptions to photographs to basic product information from an existing product data feed.
The data feed is an info file made available by your supplier, as it can be used by merchants when importing items into their stores.
No doubt, data feeds are incredibly useful for owners of eCommerce stores, particularly when dropshipping the goods.
Just note that it is crucial not to copy-paste the material of a data feed into your store without modifying it at all, since this will be considered duplicate content.
10. Image Optimization
The next suggestion on this SEO guide to raising rankings is to take your original pictures of the items.
While it could take a bit of extra work at the outset, this will help you boost your SEO rankings on dropshipping.
The next actionable move is to make the image name representative of your Alt tag.
This is one of the things many search engines use to decide about what an image is and when to show it to a search engine.
Another approach to successfully learning how to use SEO is to add titles and captions to images.
When you want to use them, they will be identical to, or the same as, the picture name and alt tag.
The title attribute should be included in the HTML section title = “insert title here”.
You don’t want to keep too many keywords, descriptive terms are also known as modifiers or other words in the image’s name or tags.
Again, this could be considered as keyword stuffing and you might be penalized for the same.
Conclusion
SEO for Dropshipping is not as easy as it seems.
You can also use a WordPress plugin that is specially designed to help dropshipping business owners.
Check out the AliDropShip Review for yourself for more clarity.
A lot is going into dropshipping SEO.
Whether you have a data feed or a dropshipping eCommerce store, or you store the product, this SEO guide provides you with the basics to optimize your store better through SEO.
The post An Ultimate Guide to SEO for Dropshipping Business in 2020 appeared first on SEO Basics.


Subscribe to MarketingSolution.
Receive web development discounts & web design tutorials.
Now! Lets GROW Together!