

Let’s start with a little section on what web scraping actually means. All of us use web scraping in our everyday lives. It merely describes the process of extracting information from a website. Hence, if you copy and paste a recipe of your favorite noodle dish from the internet to your personal notebook, you are performing “web scraping”. When using this term in the software industry, we usually refer to the automation of this manual task by using a piece of software. Sticking to our previous “noodle dish” example, this process usually involves two steps:
- Fetching the page
We first have to download the page as a whole. This step is like opening the page in your web browser when scraping manually. - Parsing the data
Now, we have to extract the recipe in the HTML of the website and convert it to a machine-readable format like JSON or XML.
In the past, I have worked for many companies as a data consultant. I was amazed to see how many data extractions, aggregation, and enrichment tasks are still done manually that could be automated with just a few lines of code. That is exactly what web scraping is all about for me: extracting and normalizing valuable pieces of information from a website to fuel another value-driving business process.
During this time, I saw companies use web scraping for all sorts of use cases. Investment firms were primarily focused on gathering alternative data, like product reviews, price information, or social media posts to underpin their financial investments. One example: A client approached me to scrape product review data for an extensive list of products from several e-commerce websites, including the rating, location of the reviewer, and the review text for each submitted review. The result data enabled the client to identify trends about the product’s popularity in different markets. This is an excellent example of how a seemingly “useless” single piece of information can become valuable when compared to a larger quantity.
Other firms accelerate their sales process by using web scraping for lead generation. This process usually involves extracting contact information like the phone number, email address, and contact name for a given list of websites. Automating this task gives sales teams more time for approaching the prospects. Hence, the efficiency of the sales process increases.
Stick To The Rules
In general, web scraping publicly available data is legal, as confirmed by the jurisdiction of the Linkedin vs. HiQ case. However, I have set myself an ethical set of rules that I like to stick to when starting a new web scraping project. This includes:
- Checking the robots.txt file.
It usually contains clear information about which parts of the site the page owner is fine to be accessed by robots & scrapers and highlights the sections that should not be accessed. - Reading the terms and conditions.
Compared to the robots.txt, this piece of information is not available less often, but usually states how they treat data scrapers. - Scraping with moderate speed.
Scraping creates server load on the infrastructure of the target site. Depending on what you scrape and at which level of concurrency your scraper is operating, the traffic can cause problems for the target site’s server infrastructure. Of course, the server capacity plays a big role in this equation. Hence, the speed of my scraper is always a balance between the amount of data that I aim to scrape and the popularity of the target site. Finding this balance can be achieved by answering a single question: “Is the planned speed going to significantly change the site’s organic traffic?”. In cases where I am unsure about the amount of natural traffic of a site, I use tools like ahrefs to get a rough idea.
Selecting The Right Technology
In fact, scraping with a headless browser is one of the least performant technologies you can use, as it heavily impacts your infrastructure. One core from your machine’s processor can approximately handle one chrome instance.
Let’s do a quick example calculation to see what this means for a real-world web scraping project.
Szenario
- You want to scrape 20,000 URLs.
- The average response time from the target site is 6 seconds.
- Your server has 2 CPU cores.
The project will take 16 hours to complete.
Hence, I always try to avoid using a browser when conducting a scraping feasibility test for a dynamic website.
Here is a small checklist that I always go through:
☐ Can I force the required page state through GET-parameters in the URL? If yes, we can simply run an HTTP-request with the appended parameters.
☐ Are the dynamic information part of the page source and available through a javascript object somewhere in the DOM? If yes, we can again use a normal HTTP-request and parse the data from the stringified object.
☐ Are the data fetched through an XHR-request? If so, can I directly access the endpoint with an HTTP-client? If yes, we can send an HTTP-request to the endpoint directly. A lot of times, the response is even formatted in JSON, which makes our life much easier.
If all questions are answered with a definite “NO”, we officially run out of feasible options for using an HTTP-client. Of course, there might be more site-specific tweaks that we could try, but usually, the required time to figure them out is too high, compared to the slower performance of a headless browser. The beauty of scraping with a browser is that you can scrape anything that is subject to the following basic rule:
If you can see it with a browser, you can scrape it.
Let’s take the following site as an example for our scraper: https://quotes.toscrape.com/search.aspx. It features quotes from a list of given authors for a list of topics. All data is fetched via XHR.
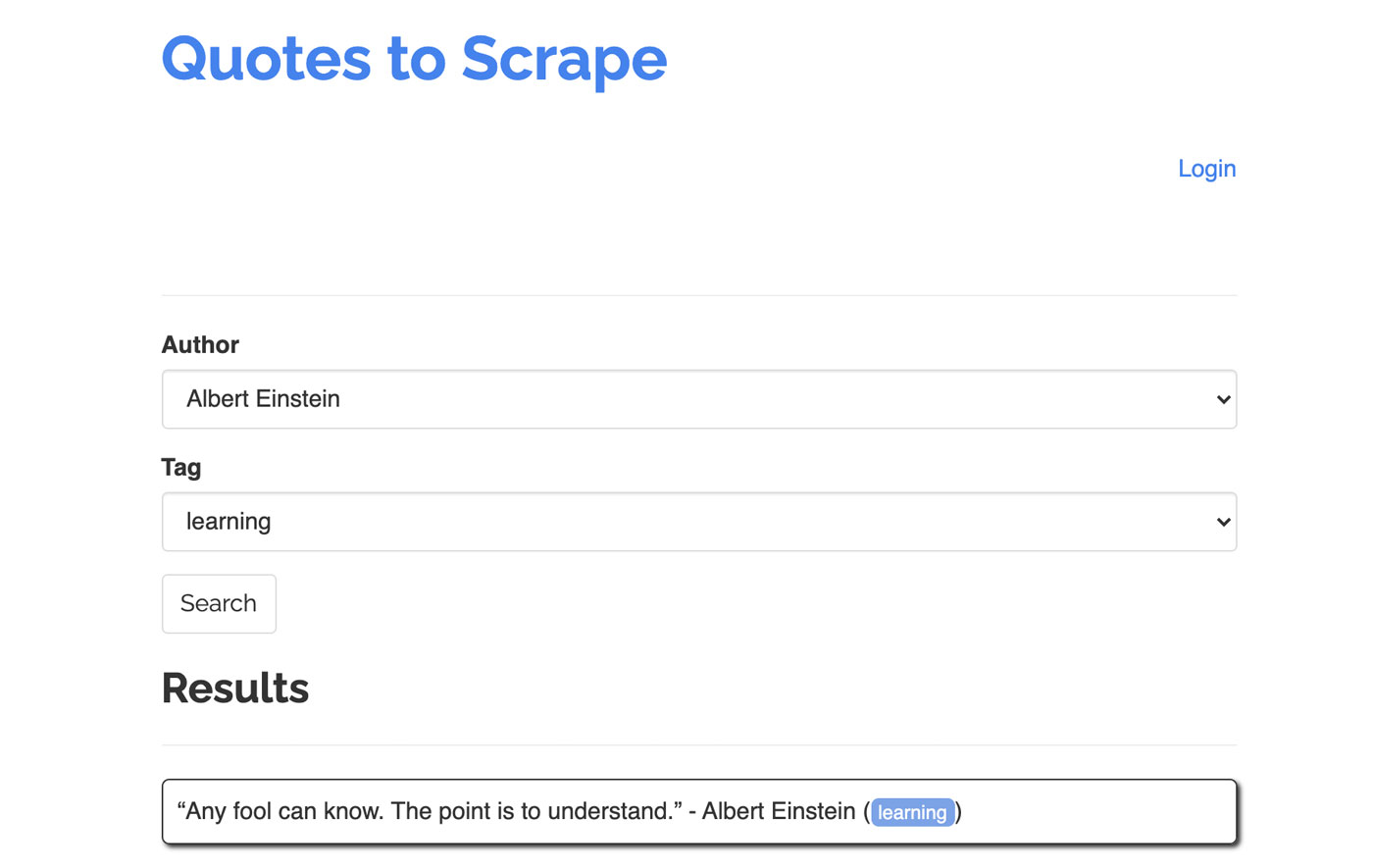
Whoever took a close look at the site’s functioning and went through the checklist above probably realized that the quotes could actually be scraped using an HTTP-client, as they can be retrieved by making a POST-request on the quotes endpoint directly. But since this tutorial is supposed to cover how to scrape a website using Puppeteer, we will pretend this was impossible.
Installing Prerequisites
Since we are going to build everything using Node.js, let’s first open a new folder and create a new node project inside, running the following command:
mkdir js-webscraper
cd js-webscraper
npm initPlease make sure you have previously installed the packaging manager npm.
The installer will ask us a few questions about meta-information about this project, which we can all skip, hitting enter.
Installing Puppeteer
We have been talking about scraping with a browser before. Puppeteer is a NodeJS API that allows us to talk to a headless chrome instance programmatically.
Let’s install it using npm:
npm install puppeteerBuilding Our Scraper
Now, let’s start to build our scraper by creating a new file, called scraper.js.
First, we import the previously installed library, Puppeteer:
const puppeteer = require('puppeteer');As a next step, we tell Puppeteer to open up a new browser instance inside an asynchronous and self-executing function:
(async function scrape() {
const browser = await puppeteer.launch({ headless: false });
// scraping logic comes here…
})();Note: By default, the headless mode is switched off, as this increases performance. However, when building a new scraper, I like to turn off the headless mode. This allows us to follow the process the browser is going through and see all rendered content. This will help us to debug our script later on.
Inside our opened browser instance, we now open a new page and direct towards our target URL:
const page = await browser.newPage();
await page.goto('https://quotes.toscrape.com/search.aspx');As part of the asynchronous function, we will use the await statement to wait for the following command to be executed before proceeding with the next line of code.
Now that we have successfully opened a browser window and navigated to the page, we have to create the website’s state, so the desired pieces of information become visible for scraping.
The available topics are generated dynamically for a selected author. Hence, we will first select ‘Albert Einstein’ and wait for the generated list of topics. Once the list has been fully generated, we select ‘learning’ as a topic and select it as a second form parameter. We then click on submit and extract the retrieved quotes from the container that is holding the results.
As we will now convert this into javascript logic, let’s first make a list of all element-selector that we have talked about in the previous paragraph:
| author select-field | #author |
| tag select-field | #tag |
| submit button | input[type=”submit”] |
| quote-container | .quote |
Before we start interacting with the page, we will ensure that all elements that we will access are visible, by adding the following lines to our script:
await page.waitForSelector('#author');
await page.waitForSelector('#tag');Next, we will select values for our two select fields:
await page.select('select#author', 'Albert Einstein');
await page.select('select#tag', 'learning');We are now ready to conduct our search by hitting the “Search” button on the page and wait for the quotes to appear:
await page.click('.btn');
await page.waitForSelector('.quote');Since we are now going to access the HTML DOM-structure of the page, we are calling the provided page.evaluate() function, selecting the container that is holding the quotes (it is only one in this case). We then build an object and define null as the fallback-value for each object parameter:
let quotes = await page.evaluate(() => {
let quotesElement = document.body.querySelectorAll('.quote');
let quotes = Object.values(quotesElement).map(x => {
return {
author: x.querySelector('.author').textContent ?? null,
quote: x.querySelector('.content').textContent ?? null,
tag: x.querySelector('.tag').textContent ?? null,
};
});
return quotes;
});We can make all results visible in our console by logging them:
console.log(quotes);Finally, let’s close our browser and add a catch statement:
await browser.close();The complete scraper looks like the following:
const puppeteer = require('puppeteer');
(async function scrape() {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://quotes.toscrape.com/search.aspx');
await page.waitForSelector('#author');
await page.select('#author', 'Albert Einstein');
await page.waitForSelector('#tag');
await page.select('#tag', 'learning');
await page.click('.btn');
await page.waitForSelector('.quote');
// extracting information from code
let quotes = await page.evaluate(() => {
let quotesElement = document.body.querySelectorAll('.quote');
let quotes = Object.values(quotesElement).map(x => {
return {
author: x.querySelector('.author').textContent ?? null,
quote: x.querySelector('.content').textContent ?? null,
tag: x.querySelector('.tag').textContent ?? null,
}
});
return quotes;
});
// logging results
console.log(quotes);
await browser.close();
})();
Let’s try to run our scraper with:
node scraper.jsAnd there we go! The scraper returns our quote object just as expected:

Advanced Optimizations
Our basic scraper is now working. Let’s add some improvements to prepare it for some more serious scraping tasks.
Setting A User-Agent
By default, Puppeteer uses a user-agent that contains the string ‘HeadlessChrome’. Quite a few websites lookout for this sort of signature and block incoming requests with a signature like this. To avoid that from being a potential reason for the scraper to fail, I always set a custom user-agent by adding the following line to our code:
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36');This could be improved even further by choosing a random user-agent with each request from an array of the top 5 most common user-agents. A list of the most common user-agents can be found here.
Implementing A Proxy
Puppeteer makes connecting to a proxy very easy, as the proxy address can be passed to puppeteer up on launch, like below:
const browser = await puppeteer.launch({
headless: false,
args: [ '--proxy-server=<PROXY-ADDRESS>' ]
});sslproxies provides a large list of free proxies that you can use. Alternatively, rotating proxy services can be used. As proxies are usually shared between many customers (or free users in this case), the connection becomes much more unreliable than it already is under normal circumstances. This is the perfect moment to talk about error handling and retry-management.
Error And Retry-Management
A lot of factors can cause your scraper to fail. Hence, it is important to handle errors and decide what should happen in case of a failure. Since we have connected our scraper to a proxy and expect the connection to be unstable (especially because we are using free proxies), we want to retry four times before giving up.
Also, there is no point in retrying a request with the same IP address again if it has previously failed. Hence, we are going to build a small proxy rotating system.
First of all, we create two new variables:
let retry = 0;
let maxRetries = 5;Each time we are running our function scrape(), we will increase our retry variable by 1. We then wrap our complete scraping logic with a try and catch statement so we can handle errors. The retry-management happens inside our catch function:
The previous browser instance will be closed, and if our retry variable is smaller than our maxRetries variable, the scrape function is called recursively.
Our scraper will now look like this:
const browser = await puppeteer.launch({
headless: false,
args: ['--proxy-server=' + proxy]
});
try {
const page = await browser.newPage();
… // our scraping logic
} catch(e) {
console.log(e);
await browser.close();
if (retry < maxRetries) {
scrape();
}
};Now, let us add the previously mentioned proxy rotator:
Let’s first create an array containing a list of proxies:
let proxyList = [
'202.131.234.142:39330',
'45.235.216.112:8080',
'129.146.249.135:80',
'148.251.20.79'
];Now, pick a random value from the array:
var proxy = proxyList[Math.floor(Math.random() * proxyList.length)];We can now run the dynamically generated proxy together with our Puppeteer instance:
const browser = await puppeteer.launch({
headless: false,
args: ['--proxy-server=' + proxy]
});Of course, this proxy rotator could be further optimized to flag dead proxies, and so on, but this would definitely go beyond the scope of this tutorial.
This is the code of our scraper (including all improvements):
const puppeteer = require('puppeteer');
// starting Puppeteer
let retry = 0;
let maxRetries = 5;
(async function scrape() {
retry++;
let proxyList = [
'202.131.234.142:39330',
'45.235.216.112:8080',
'129.146.249.135:80',
'148.251.20.79'
];
var proxy = proxyList[Math.floor(Math.random() * proxyList.length)];
console.log('proxy: ' + proxy);
const browser = await puppeteer.launch({
headless: false,
args: ['--proxy-server=' + proxy]
});
try {
const page = await browser.newPage();
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36');
await page.goto('https://quotes.toscrape.com/search.aspx');
await page.waitForSelector('select#author');
await page.select('select#author', 'Albert Einstein');
await page.waitForSelector('#tag');
await page.select('select#tag', 'learning');
await page.click('.btn');
await page.waitForSelector('.quote');
// extracting information from code
let quotes = await page.evaluate(() => {
let quotesElement = document.body.querySelectorAll('.quote');
let quotes = Object.values(quotesElement).map(x => {
return {
author: x.querySelector('.author').textContent ?? null,
quote: x.querySelector('.content').textContent ?? null,
tag: x.querySelector('.tag').textContent ?? null,
}
});
return quotes;
});
console.log(quotes);
await browser.close();
} catch (e) {
await browser.close();
if (retry < maxRetries) {
scrape();
}
}
})();
Running the scraper inside our terminal will return the quotes, as above.
Playwright As An Alternative To Puppeteer
Puppeteer was developed by Google. At the beginning of 2020, Microsoft released an alternative called Playwright. Microsoft headhunted a lot of engineers from the Puppeteer-Team. Hence, Playwright was developed by a lot of engineers that already got their hands dirty on Puppeteer. Besides being the new kid on the blog, Playwright’s biggest differentiating point is the cross-browser support, as it supports Chromium, Firefox, and WebKit(Safari).
Performance tests (like this one conducted by Checkly) show that puppeteer generally provides about 30% better performance, compared to Playwright, which matches my own experience.
Other differences, like the fact that you can run multiple devices with one browser instance, are not really valuable for the context of web scraping.


Subscribe to MarketingSolution.
Receive web development discounts & web design tutorials.
Now! Lets GROW Together!