
(This can be a sponsored submit.)
On this article, we’ll focus on how we are able to apply schema stitching throughout a number of Fauna cases. We will even focus on tips on how to mix different GraphQL providers and information sources with Fauna in a single graph.
What’s Schema Stitching?
Schema stitching is the method of making a single GraphQL API from a number of underlying GraphQL APIs.
The place is it helpful?
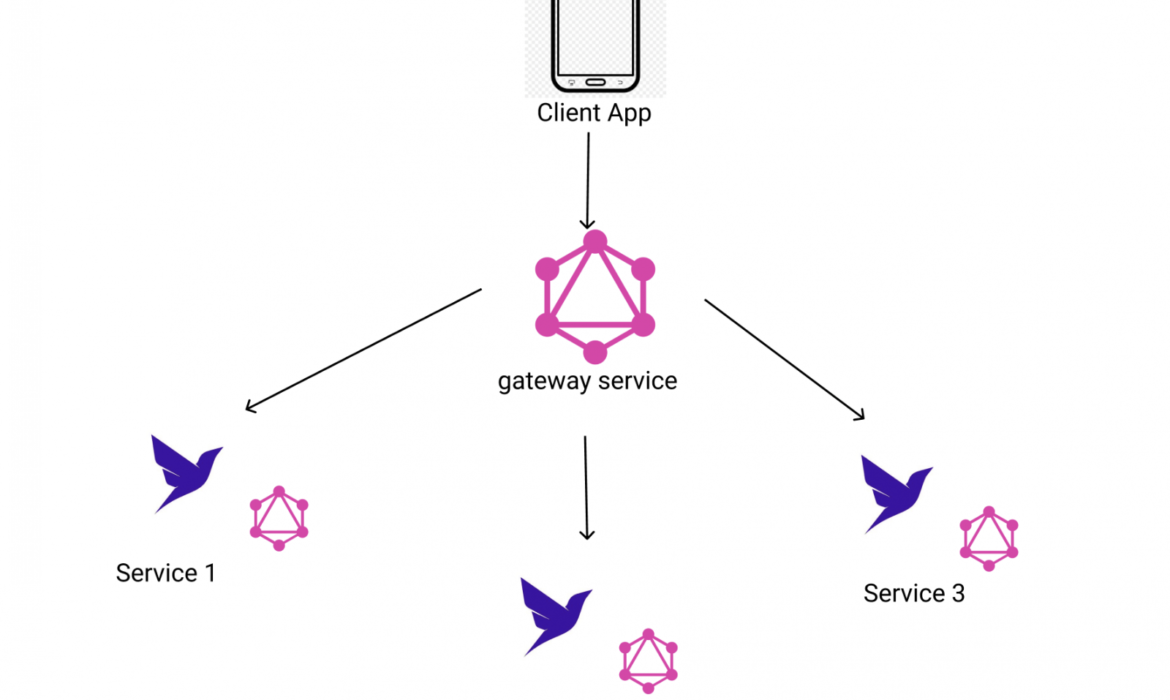
Whereas constructing large-scale purposes, we frequently break down numerous functionalities and enterprise logic into micro-services. It ensures the separation of issues. Nonetheless, there shall be a time when our shopper purposes want to question information from a number of sources. The perfect observe is to show one unified graph to all of your shopper purposes. Nonetheless, this could possibly be difficult as we don’t wish to find yourself with a tightly coupled, monolithic GraphQL server. If you’re utilizing Fauna, every database has its personal native GraphQL. Ideally, we’d wish to leverage Fauna’s native GraphQL as a lot as attainable and keep away from writing utility layer code. Nonetheless, if we’re utilizing a number of databases our front-end utility must hook up with a number of GraphQL cases. Such association creates tight coupling. We wish to keep away from this in favor of 1 unified GraphQL server.
To treatment these issues, we are able to use schema stitching. Schema stitching will enable us to mix a number of GraphQL providers into one unified schema. On this article, we’ll focus on
Combining a number of Fauna cases into one GraphQL serviceCombining Fauna with different GraphQL APIs and information sourcesHow to construct a serverless GraphQL gateway with AWS Lambda?
Combining a number of Fauna cases into one GraphQL service
First, let’s check out how we are able to mix a number of Fauna cases into one GraphQL service. Think about we’ve three Fauna database cases Product, Stock, and Overview. Every is impartial of the opposite. Every has its graph (we’ll consult with them as subgraphs). We wish to create a unified graph interface and expose it to the shopper purposes. Shoppers will be capable to question any mixture of the downstream information sources.
We’ll name the unified graph to interface our gateway service. Let’s go forward and write this service.
We’ll begin with a recent node mission. We’ll create a brand new folder. Then navigate inside it and provoke a brand new node app with the next instructions.
mkdir my-gateway
cd my-gateway
npm init –yes
Subsequent, we’ll create a easy specific GraphQL server. So let’s go forward and set up the specific and express-graphqlpackage with the next command.
npm i specific express-graphql graphql –save
Creating the gateway server
We’ll create a file known as gateway.js . That is our major entry level to the applying. We’ll begin by making a quite simple GraphQL server.
const specific = require(‘specific’);
const { graphqlHTTP } = require(‘express-graphql’);
const { buildSchema } = require(‘graphql’);
// Assemble a schema, utilizing GraphQL schema language
const schema = buildSchema(`
kind Question {
whats up: String
}
`);
// The basis supplies a resolver operate for every API endpoint
const rootValue = {
whats up: () => ‘Hey world!’,
};
const app = specific();
app.use(
‘/graphql’,
graphqlHTTP((req) => ({
schema,
rootValue,
graphiql: true,
})),
);
app.pay attention(4000);
console.log(‘Working a GraphQL API server at <http://localhost:4000/graphql>’);
Within the code above we created a bare-bone express-graphql server with a pattern question and a resolver. Let’s check our app by operating the next command.
node gateway.js
Navigate to [<http://localhost:4000/graphql>](<http://localhost:4000/graphql>) and it is possible for you to to work together with the GraphQL playground.
Creating Fauna cases
Subsequent, we’ll create three Fauna databases. Every of them will act as a GraphQL service. Let’s head over to fauna.com and create our databases. I’ll title them Product, Stock and Overview
As soon as the databases are created we’ll generate admin keys for them. These keys are required to connect with our GraphQL APIs.
Let’s create three distinct GraphQL schemas and add them to the respective databases. Right here’s how our schemas will look.
# Schema for Stock database
kind Stock {
title: String
description: String
sku: Float
availableLocation: [String]
}
# Schema for Product database
kind Product {
title: String
description: String
value: Float
}
# Schema for Overview database
kind Overview {
electronic mail: String
remark: String
ranking: Float
}
Head over to the relative databases, choose GraphQL from the sidebar and import the schemas for every database.
Now we’ve three GraphQL providers operating on Fauna. We are able to go forward and work together with these providers by the GraphQL playground inside Fauna. Be happy to enter some dummy information in case you are following alongside. It would turn out to be useful later whereas querying a number of information sources.
Organising the gateway service
Subsequent, we’ll mix these into one graph with schema stitching. To take action we’d like a gateway server. Let’s create a brand new file gateway.js. We shall be utilizing a few libraries from graphql instruments to sew the graphs.
Let’s go forward and set up these dependencies on our gateway server.
npm i @graphql-tools/schema @graphql-tools/sew @graphql-tools/wrap cross-fetch –save
In our gateway, we’re going to create a brand new generic operate known as makeRemoteExecutor. This operate is a manufacturing facility operate that returns one other operate. The returned asynchronous operate will make the GraphQL question API name.
// gateway.js
const specific = require(‘specific’);
const { graphqlHTTP } = require(‘express-graphql’);
const { buildSchema } = require(‘graphql’);
operate makeRemoteExecutor(url, token) {
return async ({ doc, variables }) => {
const question = print(doc);
const fetchResult = await fetch(url, {
methodology: ‘POST’,
headers: { ‘Content material-Kind’: ‘utility/json’, ‘Authorization’: ‘Bearer ‘ + token },
physique: JSON.stringify({ question, variables }),
});
return fetchResult.json();
}
}
// Assemble a schema, utilizing GraphQL schema language
const schema = buildSchema(`
kind Question {
whats up: String
}
`);
// The basis supplies a resolver operate for every API endpoint
const rootValue = {
whats up: () => ‘Hey world!’,
};
const app = specific();
app.use(
‘/graphql’,
graphqlHTTP(async (req) => {
return {
schema,
rootValue,
graphiql: true,
}
}),
);
app.pay attention(4000);
console.log(‘Working a GraphQL API server at http://localhost:4000/graphql’);
As you may see above the makeRemoteExecutor has two parsed arguments. The url argument specifies the distant GraphQL url and the token argument specifies the authorization token.
We’ll create one other operate known as makeGatewaySchema. On this operate, we’ll make the proxy calls to the distant GraphQL APIs utilizing the beforehand created makeRemoteExecutor operate.
// gateway.js
const specific = require(‘specific’);
const { graphqlHTTP } = require(‘express-graphql’);
const { introspectSchema } = require(‘@graphql-tools/wrap’);
const { stitchSchemas } = require(‘@graphql-tools/sew’);
const { fetch } = require(‘cross-fetch’);
const { print } = require(‘graphql’);
operate makeRemoteExecutor(url, token) {
return async ({ doc, variables }) => {
const question = print(doc);
const fetchResult = await fetch(url, {
methodology: ‘POST’,
headers: { ‘Content material-Kind’: ‘utility/json’, ‘Authorization’: ‘Bearer ‘ + token },
physique: JSON.stringify({ question, variables }),
});
return fetchResult.json();
}
}
async operate makeGatewaySchema() {
const reviewExecutor = await makeRemoteExecutor(‘https://graphql.fauna.com/graphql’, ‘fnAEQZPUejACQ2xuvfi50APAJ397hlGrTjhdXVta’);
const productExecutor = await makeRemoteExecutor(‘https://graphql.fauna.com/graphql’, ‘fnAEQbI02HACQwTaUF9iOBbGC3fatQtclCOxZNfp’);
const inventoryExecutor = await makeRemoteExecutor(‘https://graphql.fauna.com/graphql’, ‘fnAEQbI02HACQwTaUF9iOBbGC3fatQtclCOxZNfp’);
return stitchSchemas({
subschemas: [
{
schema: await introspectSchema(reviewExecutor),
executor: reviewExecutor,
},
{
schema: await introspectSchema(productExecutor),
executor: productExecutor
},
{
schema: await introspectSchema(inventoryExecutor),
executor: inventoryExecutor
}
],
typeDefs: ‘kind Question { heartbeat: String! }’,
resolvers: {
Question: {
heartbeat: () => ‘OK’
}
}
});
}
// …
We’re utilizing the makeRemoteExecutor operate to make our distant GraphQL executors. Now we have three distant executors right here one pointing to Product , Stock , and Overview providers. As it is a demo utility I’ve hardcoded the admin API key from Fauna instantly within the code. Keep away from doing this in an actual utility. These secrets and techniques shouldn’t be uncovered in code at any time. Please use surroundings variables or secret managers to tug these values on runtime.
As you may see from the highlighted code above we’re returning the output of the switchSchemas operate from @graphql-tools. The operate has an argument property known as subschemas. On this property, we are able to go in an array of all of the subgraphs we wish to fetch and mix. We’re additionally utilizing a operate known as introspectSchema from graphql-tools. This operate is chargeable for remodeling the request from the gateway and making the proxy API request to the downstream providers.
You possibly can be taught extra about these capabilities on the graphql-tools documentation website.
Lastly, we have to name the makeGatewaySchema. We are able to take away the beforehand hardcoded schema from our code and change it with the stitched schema.
// gateway.js
// …
const app = specific();
app.use(
‘/graphql’,
graphqlHTTP(async (req) => {
const schema = await makeGatewaySchema();
return {
schema,
context: { authHeader: req.headers.authorization },
graphiql: true,
}
}),
);
// …
After we restart our server and return to localhost we’ll see that queries and mutations from all Fauna cases can be found in our GraphQL playground.
Let’s write a easy question that can fetch information from all Fauna cases concurrently.
Sew third social gathering GraphQL APIs
We are able to sew third-party GraphQL APIs into our gateway as properly. For this demo, we’re going to sew the SpaceX open GraphQL API with our providers.
The method is similar as above. We create a brand new executor and add it to our sub-graph array.
// …
async operate makeGatewaySchema() {
const reviewExecutor = await makeRemoteExecutor(‘https://graphql.fauna.com/graphql’, ‘fnAEQdRZVpACRMEEM1GKKYQxH2Qa4TzLKusTW2gN’);
const productExecutor = await makeRemoteExecutor(‘https://graphql.fauna.com/graphql’, ‘fnAEQdSdXiACRGmgJgAEgmF_ZfO7iobiXGVP2NzT’);
const inventoryExecutor = await makeRemoteExecutor(‘https://graphql.fauna.com/graphql’, ‘fnAEQdR0kYACRWKJJUUwWIYoZuD6cJDTvXI0_Y70’);
const spacexExecutor = await makeRemoteExecutor(‘https://api.spacex.land/graphql/’)
return stitchSchemas({
subschemas: [
{
schema: await introspectSchema(reviewExecutor),
executor: reviewExecutor,
},
{
schema: await introspectSchema(productExecutor),
executor: productExecutor
},
{
schema: await introspectSchema(inventoryExecutor),
executor: inventoryExecutor
},
{
schema: await introspectSchema(spacexExecutor),
executor: spacexExecutor
}
],
typeDefs: ‘kind Question { heartbeat: String! }’,
resolvers: {
Question: {
heartbeat: () => ‘OK’
}
}
});
}
// …
Deploying the gateway
To make this a real serverless resolution we must always deploy our gateway to a serverless operate. For this demo, I’m going to deploy the gateway into an AWS lambda operate. Netlify and Vercel are the 2 different options to AWS Lambda.
I’m going to make use of the serverless framework to deploy the code to AWS. Let’s set up the dependencies for it.
npm i -g serverless # if you do not have the serverless framework put in already
npm i serverless-http body-parser –save
Subsequent, we have to make a configuration file known as serverless.yaml
# serverless.yaml
service: my-graphql-gateway
supplier:
title: aws
runtime: nodejs14.x
stage: dev
area: us-east-1
capabilities:
app:
handler: gateway.handler
occasions:
– http: ANY /
– http: ‘ANY {proxy+}’
Contained in the serverless.yaml we outline data akin to cloud supplier, runtime, and the trail to our lambda operate. Be happy to take have a look at the official documentation for the serverless framework for extra in-depth data.
We might want to make some minor adjustments to our code earlier than we are able to deploy it to AWS.
npm i -g serverless # if you do not have the serverless framework put in already
npm i serverless-http body-parser –save
Discover the highlighted code above. We added the body-parser library to parse JSON physique. Now we have additionally added the serverless-http library. Wrapping the specific app occasion with the serverless operate will care for all of the underlying lambda configuration.
We are able to run the next command to deploy this to AWS Lambda.
serverless deploy
It will take a minute or two to deploy. As soon as the deployment is full we’ll see the API URL in our terminal.
Ensure you put /graphql on the finish of the generated URL. (i.e. https://gy06ffhe00.execute-api.us-east-1.amazonaws.com/dev/graphql).
There you might have it. Now we have achieved full serverless nirvana 😉. We at the moment are operating three Fauna cases impartial of one another stitched along with a GraphQL gateway.
Be happy to take a look at the code for this text right here.
Conclusion
Schema stitching is among the hottest options to interrupt down monoliths and obtain separation of issues between information sources. Nonetheless, there are different options akin to Apollo Federation which just about works the identical method. If you want to see an article like this with Apollo Federation please tell us within the remark part. That’s it for right this moment, see you subsequent time.
The submit Implementing a single GraphQL throughout a number of information sources appeared first on CSS-Methods. You possibly can assist CSS-Methods by being an MVP Supporter.


Subscribe to MarketingSolution.
Receive web development discounts & web design tutorials.
Now! Lets GROW Together!